
k8s 调度器的调度流程和算法笔记
调度总体设计
k8s 作为一个容器编排引擎,对容器编排和调度是其核心功能。k8s 中用于调度的核心组件是 kube-scheduler。
kube-scheduler 主要分为几大组件:
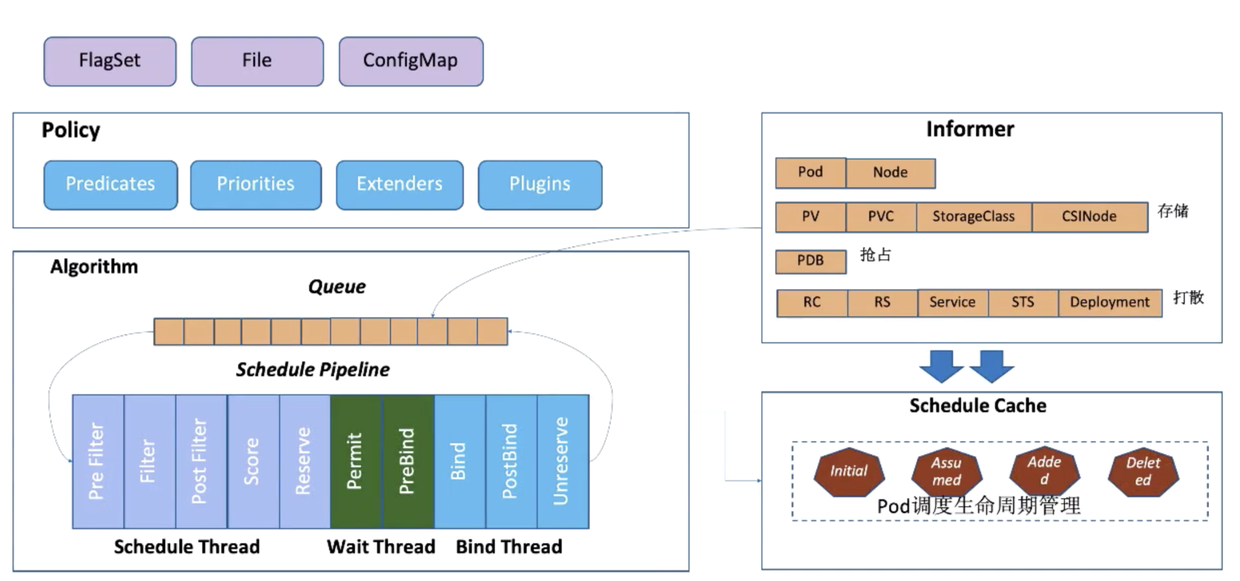
- Policy:调度策略,目前支持配置文件、命令行参数、ConfigMap 去做配置。调度策略可以指定调度流程中用的过滤器 Predicates、打分器 Priorities、外部扩展的调度器 Extenders 以及自定义扩展点 Plugins。
- Informer:scheduler 在启动的时候通过 k8s 的 informer 机制,使用 list+watch 从 kube-apiserver 获取调度需要的数据,比如 pod、nodes、PV、PVC 等,然后将这些数据做预处理作为调度器的 cache。
- 调度流水线:通过 informer 将要调度的 pod 插入 scheduler 的 Queue 中,流水线 pipeline 会循环从队列里 pop 出等待调度的 pod,放入 pipeline 执行。调度流水线分为 Scheduler Thread、Wait Thread 和 Bind Thread 三个阶段,Scheduler 阶段筛选符合 pod spec 描述的 nodes、进行打分排序、在 node cache 中分配;Wait 阶段等待 pod 关联的资源 ready,比如 pv 等;Bind 阶段将 pod 和 node 的关联持久化到 ApiServer。调度流水线只有在 scheduler thread 阶段是串行的,其他都是并行的。
调度流程
Schedulingg Queue 其实有三个子队列:activeQ、backoffQ 和 unschedulableQ。在scheduler 启动的时候,所有等待被调度的 pod 会进入 activeQ,按照 priority 进行排序,pipeline 从其中获取一个 pod 进行调度流程。如果调度失败就进入 unschedulableQ 或者 backoffQ。
unschedulableQ 会有一个较长的定期把其中的 pod 写入 activeQ 或者 backoffQ,而 backoffQ 的定期时间更短。
在 Scheduler Thread 阶段,当 pipeline 拿到一个 pod,会从 nodeCache 里拿到相关的 Node 执行 filter 逻辑匹配。这个逻辑匹配采用取样调度的方法,也就是说会根据一个取样率决定一个取样规模,filter 只要取到这个数量的候选节点就可以停止 filter 阶段了。
在 Score 阶段,根据 policy 配置的算分插件,会将候选节点进行排序,选择分数最高的节点。
在 Reserve阶段,会修改 pod 在 podCache 里的状态为 Assumed,进行资源的预占。
对于 pod 来说,其生命周期主要有 init->assumed->added->deleted 几种状态。在 reserve 阶段 pod 可以被修改至 assumed,而只有在 informer watch 到 pod 数据已确定分配到这个节点的时候才会更新到 added。选完节点在 bind 阶段的时候可能会失败,如果失败会进行回退,将 assumed 的预占信息退回 init,从 node 里把 pod 账本清除,并把 pod 丢到 unschedulableQ 中。此外,如果在一个调度周期内 nodeCache 或 Pod Cache 发生了变化,会把 pod 放到 backoffQ 里。backoffQ 有相较于 unschedulableQ 更短的重试时间,同时配有一个降级策略,让重试时间依次增加。
调度算法实现
过滤器
过滤器用于过滤筛选符合条件的节点,根据功能可以分成四类:
- 存储相关:存储相关的过滤器有校验最大 pv 数限制、磁盘分区校验、binding 过程的逻辑校验等
- pod 和 node 匹配相关:检查节点是否准备好被调度、有无不可调度标记、节点的污点(taint)是否可以被 pod tolerates 包含、pod 的节点亲和以及 node selector 设置 是否和 node 的 label 匹配等
- pod 和 pod 匹配相关:检查 pod 亲和性是否满足
- 一些跟 pod 打散相关的逻辑检查。
打分
打分算法主要解决集群的碎片、容灾、水位、亲和等问题:
资源水位
-
定义 request 为 node 已分配的资源;allocatable 为 node 可调度的资源
-
资源空闲率 = (allocatable - request)/allocatable,资源使用率 = request/allocatable
-
打分算法若选择优先打散,则会把 pod 分到资源空闲率最高的节点上,而非空闲资源最大的节点。也就是资源空闲率越大、分数越高。
-
打分算法若选择优先堆叠,则会分配到资源使用率最高的节点上
-
打分算法若选择碎片率,则会选择 CPU/Mem/Disk 三类资源中差值最大的一个。例如,cpu分配率 99%、内存分配率 50% 的 node 碎片率就是 49%。碎片率越高,这类规格容器就越难有效利用其中一类资源,因此碎片率越高得分越低。
-
指定比率:为每种资源指定一个权重,从而自定义控制 node 的资源分配分布曲线
亲和/反亲和
- 根据亲和度满足情况计分
- 根据 label 提高/降低打分
- 本地已有镜像的节点高分
Pod QoS
Quality of Service,用来表达一个 pod 在资源能力上的服务质量的标准,分为三类:
- Guaranteed:是一种高 QoS 的等级,一般配置给高资源保证要求的 pods;
- Burstable:中等的 QoS 等级,会为希望有弹性能力的 pod 配置;
- BestEffort,低 QoS 等级,尽力而为,不保证这类 pod 的服务质量。
对用户来说,这几种 QoS 不是手动设置的,而是会根据用户设置的 resource 的 request 和 limit 来自动的映射:
- request:保底资源需求,需要保障的最小值
- limits:可用资源的上限
用户资源设置对应 QoS 的规则:
- 当用户设置基础的两种资源(cpu和memory)的 request == limit 时,k8s 会将这个 pod 设为 Guaranteed。
- 如果用户设置两种基础资源的 request 和 limit 不相等,这个 pod 就是 Burstable Pod。
- 如果用户不填写这两种资源的 request 和 limit,就会被归为 bestEffort pod。
在不同 QoS 上,k8s 在调度和底层表现上会有所不同:
- 在调度时调度器只会考虑 request,而不考虑 limit;
- 高 QoS 能获得的时间片权重远高于低 QoS;
- 内存按 QoS 来划分 OOMScore,因此低 QoS 的 pod 会优先被 kill;
- 在驱逐 eviction 动作上,会优先考虑驱逐低 QoS 的 pod。
资源 Quota
k8s 提供了资源 Quota 功能,可以限制某个 Namespace 的资源用量,避免不合理挤占。
使用资源 Quota,可以定义 v1.ResourceQuota 来完成。它的 resource 不一定要填写三种基础资源,也可以写例如 pod 数量限制等。此外,配合 scopeSelector,可以做一些高级的标签匹配,限制自定义类型的资源。
建立了 ResourceQuota 作用于 Namespace 后,如果用户用超了资源,在提交 pod spec 的时候就会收到一个 403 forbidden 的错误,并且提示 exeed quota。
使用 ResourceQuota 可以限制一个 namespace 里的资源用量,保证其他用户的资源使用。
优先级调度
k8s 的调度器还提供了优先级调度的功能,从而提供了一种抢占机制。也就是如果在资源不够的情况下,有更高优先级的 pod 等待调度时,应该驱逐低优先级 pod,将其放回等待队列,让高优先级 pod 抢占。
在使用时,首先要定义一个 priorityClass,然后再为每个 pod 配置上不同的 priorityClassName。每个 priorityClass 都有一个整数来标志优先级。k8s 也内置了两个系统级别优先级,且高于用户设置优先级。
在进行调度时,如果在资源充足情况下(无抢占),两 pod 先后进入调度队列但未被调度,则 pq 会优先 pop 出高优 pod 出队进行调度;调度成功后,对此 pod 进行 bind,然后再在下一轮调度低优 pod。
在资源不足时,假设有低优 pod 2 先到达并获得分配,之后高优 pod1 调度,但因为资源不足导致调度失败,于是进入抢占流程;在抢占算法计算后,选中了 pod2 作为 pod1 的让渡者,随后驱逐 pod2,将 pod 1 进行调度。
那么如何挑选被抢占节点(Node)呢?
- 优先选择打破 PDB(中断预算,表示在故障情况下可以同时中断 pod 数量的上限)最少的节点(受故障或资源限制影响最小的节点)
- 其次选择待抢占 pods 中最大优先级最小的节点
- 再次选择待抢占 pods 中优先级的和最小的节点
- 再次选择待抢占 pods 的数量最少的节点
- 最后选择拥有最晚启动 pod 的节点
总结
一段话总结:
kubernetes 使用 kube-scheduler 组件来进行容器的调度。scheduler 包括调度策略、Informer和调度流水线三部分,调度策略可以由用户指定和扩展,决定了调度过程中的节点过滤、打分等流程的策略,Informer 负责以 list+watch 机制从 apiserver 获取调度需要的如 pod、node、pv 等数据;调度流水线维护优先队列,串行执行 scheduler 阶段为 pod 选择节点并预分配资源,然后并行执行 wait 和 bind 阶段等待和最终持久化关联 pod 到分配的节点。此外,调度器的调度策略还可以受用户指定的资源水位、亲和度、优先级和 QoS 影响。