
etcd 分布式 k-v 存储与 raft 应用 上
一起读,@CD (
简介
etcd 是 go 语言实现的 分布式 k-v 存储,通过 raft 协议维护一致性,对外提供强一致性和高可用性。强一致性意味着超过最终一致性的可靠性,它可以有效应对各种类型的网络问题和机器故障问题,常用于提供高可靠要求的服务发现、分布式锁、分布式消息队列等功能。作为 CNCF 的核心项目,etcd 现在在 kubernetes 中用于维护集群的各种状态和元信息,保证这些信息的实时同步和持久化。
etcd 的 github 开源地址:etcd-io/etcd: Distributed reliable key-value store for the most critical data of a distributed system (github.com)
etcd 提供的能力包括:
- 存储和获取数据的接口(get set)并保证数据的强一致性
- 监听机制,可以监听 key 的变更
- 提供 key 的过期和续约
- 提供原子的 CAS(Compare-and-Swap)和 CAD(Compare-and-Delete)支持
etcd 经常作为一个 raft 的工程案例讲解,所以这里主要总结一下 etcd 对 raft 进行的应用和有关实现。
架构
etcd 在实现 raft 时将模块拆分为应用层和算法层两个模块。其中算法层是一个被应用层引用的静态库,在程序中两个模块会分布在两个独立的 goroutine 中,使用 channel 进行模块间通信。注意这里只讨论和 raft 有关的部分,不考虑其他功能层。另外代码主要以 v3 为准,v3 引入了 grpc,所以可以在数据结构里看到 pb 的 tag。
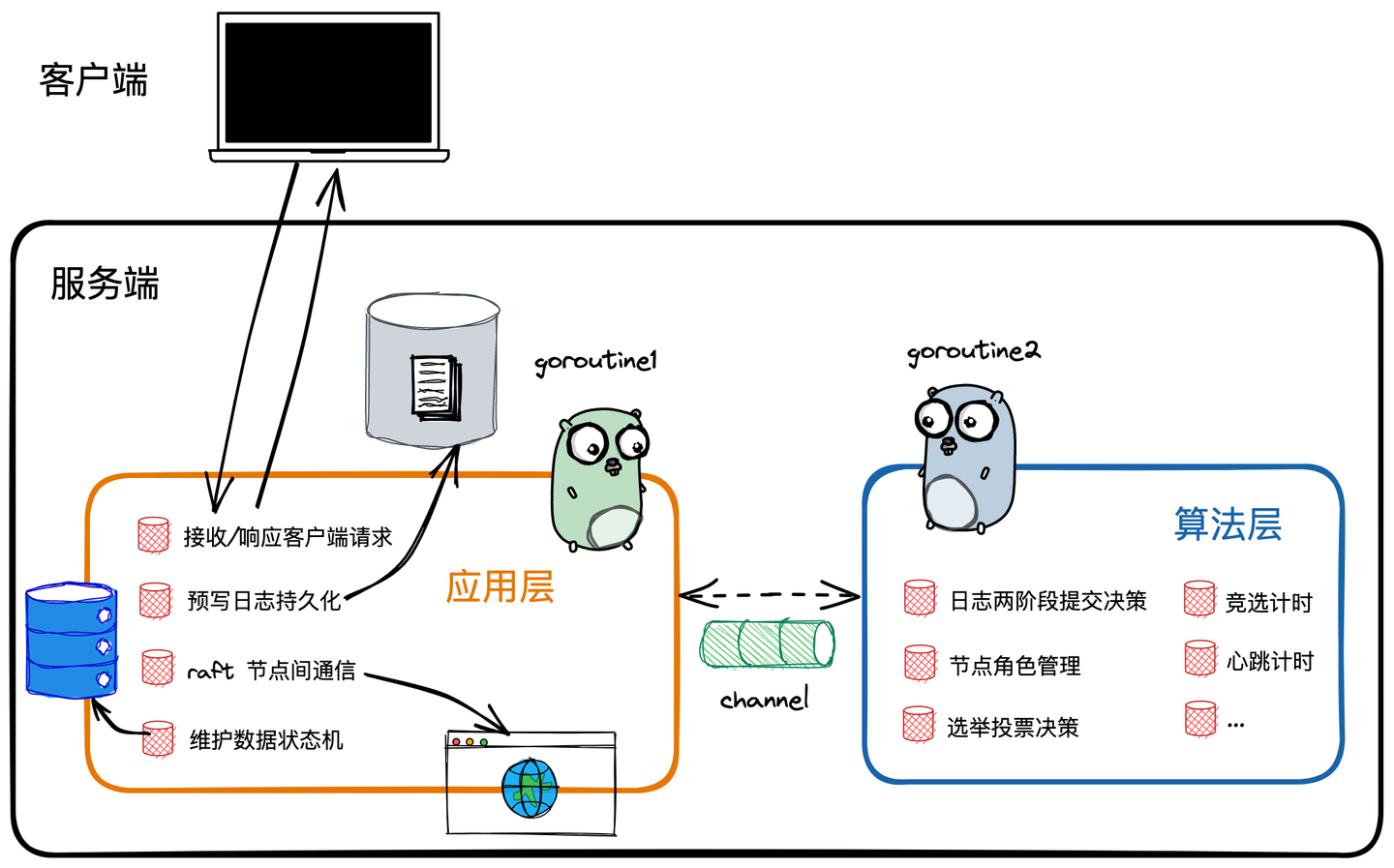
算法层
算法是架构中专门用来实现 raft 算法的核心模块,主要工作是根据共识机制进行请求内容的正确性校验、对预写日志(write ahead log,WAL)的状态进行维护,以及可提交日志的进度推进,就是 raft 的那一套机制。
总之,算法层主要负责把应用层传来的输入日志做共识,然后返回达成一致的日志。
应用层
应用层是相对于 raft 算法面向服务对象的应用层,是 raft 节点里的中间层,向上与外部客户端通信,向下使用算法库,同时负责和其他模块交互。应用层主要涉及到网络通信、日志持久化、状态机管理等。
算法层数据结构
接下来看看算法层的一些核心数据结构。
首先是 Entry,和 raft 定义一致,一条 Entry 就是一笔预写日志,包含了普通类型和配置变更两种:
const (
EntryNormal EntryType = 0
// 配置变更类的日志
EntryConfChange EntryType = 1
)
type Entry struct {
Term uint64 `protobuf:"varint,2,opt,name=Term" json:"Term"`
Index uint64 `protobuf:"varint,3,opt,name=Index" json:"Index"`
Type EntryType `protobuf:"varint,1,opt,name=Type,enum=raftpb.EntryType" json:"Type"`
Data []byte `protobuf:"bytes,4,opt,name=Data" json:"Data,omitempty"`
}
Entry 包含了任期、索引、Data 三个字段。根据 raft 算法,term 和 indedx 构成了 entry 的全局索引。
对于 raft 算法来说,节点本质上是一个状态机,由输入的消息来不断地进行状态变更。这个改变状态机的输入消息就是 Message 结构体:
type Message struct {
Type MessageType `protobuf:"varint,1,opt,name=type,enum=raftpb.MessageType" json:"type"`
To uint64 `protobuf:"varint,2,opt,name=to" json:"to"`
From uint64 `protobuf:"varint,3,opt,name=from" json:"from"`
Term uint64 `protobuf:"varint,4,opt,name=term" json:"term"`
LogTerm uint64 `protobuf:"varint,5,opt,name=logTerm" json:"logTerm"`
Index uint64 `protobuf:"varint,6,opt,name=index" json:"index"`
Entries []Entry `protobuf:"bytes,7,rep,name=entries" json:"entries"`
Commit uint64 `protobuf:"varint,8,opt,name=commit" json:"commit"`
// ...
Reject bool `protobuf:"varint,10,opt,name=reject" json:"reject"`
RejectHint uint64 `protobuf:"varint,11,opt,name=rejectHint" json:"rejectHint"`
// ...
}
Message 包含了日志同步消息、leader 选举消息、心跳消息等等内容,全都放在 MessageType里。(颇有我自己实现时候的不良美感)
需要注释的是,LogTerm、Index 对应的是 raft 论文的 LastLogTerm 和 LastLogIndex;Entries 是要完成同步的日志列表;Commit 是 leader 已提交的日志 inedx;Reject 标识响应结果为拒绝或赞同;RejectHint 用于日志同步时快速寻找冲突点(参考论文原文)。
raftLog 负责管理算法层里的预写日志,包含未持久和持久化的日志查询:
type raftLog struct {
// 用于保存自从最后一次snapshot之后提交的数据
storage Storage
// 用于保存还没有持久化的数据和快照,这些数据最终都会保存到storage中
unstable unstable
// committed数据索引
committed uint64
// committed保存是写入持久化存储中的最高index,而applied保存的是传入状态机中的最高index
// 即一条日志首先要提交成功(即committed),才能被applied到状态机中
// 因此以下不等式一直成立:applied <= committed
applied uint64
// ...
}
这里的 Storage 是论文里没有的持久化日志的存储接口:
type Storage interface {
// 返回保存的初始状态
InitialState() (pb.HardState, pb.ConfState, error)
// 返回索引范围在[lo,hi)之内并且不大于maxSize的entries数组
Entries(lo, hi, maxSize uint64) ([]pb.Entry, error)
// 传入一个索引值,返回这个索引值对应的任期号,如果不存在则error不为空,其中:
// ErrCompacted:表示传入的索引数据已经找不到,说明已经被压缩成快照数据了。
// ErrUnavailable:表示传入的索引值大于当前的最大索引
Term(i uint64) (uint64, error)
// 获得最后一条数据的索引值
LastIndex() (uint64, error)
// 返回第一条数据的索引值
FirstIndex() (uint64, error)
// ...
}
这个东西主要就是维护持久化日志的查询能力。
剩下未持久化的数据就留给 unstable 结构去管理:
type unstable struct {
// ...
// 还未持久化的数据
entries []pb.Entry
// offset用于保存entries数组中的数据的起始index
offset uint64
// ...
}
其实就是一个未持久化log的列表,并维护一个在全局 logEntries 里的偏移量。
关于算法层与应用层交互的数据结构,etcd 里叫做 Ready,每当算法层完成一轮处理逻辑,就会往 channel 里塞一个这东西,封装处理好的结果:
type Ready struct {
// 软状态是异变的,包括:当前集群leader、当前节点状态
*SoftState
// 硬状态需要被保存,包括:节点当前Term、Vote、Commit
// 如果当前这部分没有更新,则等于空状态
pb.HardState
// 需要在消息发送之前被写入到持久化存储中的entries数据数组
Entries []pb.Entry
// ...
// 需要输入到状态机中的数据数组,这些数据之前已经被保存到持久化存储中了
CommittedEntries []pb.Entry
// 在entries被写入持久化存储中以后,需要发送出去的数据
Messages []pb.Message
}
-
其中 SoftState 标识 raft 节点的软状态,就是不做持久化、通过协议机制和通信来维护的一些状态信息,包括自己的 leader 信息和自己的职位信息;
-
HardState 是 raft 节点的当前 term、自己投票的目标和自己已 commit 的 index,这部分信息根据 raft 协议必须要持久化;
-
Entries 是本轮算法层产生的 log 的列表,需要由应用层来完成持久化;
-
CommittedEntris 如其名,是本轮算法层已提交的 log,下面的工作是由应用层应用到状态机;
-
Message 是本轮算法层要往外发的网络信息,由应用层调网络模块发出。
至此,有了两层交换的数据结构,肯定也要有交换的接口,etcd 叫做 Node,主要对算法层的 raft 节点做抽象,负责两层的交互:
// Node represents a node in a raft cluster.
type Node interface {
Tick()
Propose(ctx context.Context, data []byte) error
ProposeConfChange(ctx context.Context, cc pb.ConfChange) error
ApplyConfChange(cc pb.ConfChange) *pb.ConfState
ReadIndex(ctx context.Context, rctx []byte) error
Step(ctx context.Context, msg pb.Message) error
Ready() <-chan Ready
Advance()
// ...
}
-
Tick:定时驱动信号,leader 心跳计时和选举计时都是以 tick 为单位;
-
Propose:应用层向算法层发起一笔写数据的请求,向 channel 传入一条消息,算法层的 goroutine 读到以后会驱动 raft 节点进入写请求的提议流程;
-
ProposeConfChange:应用层推动 raft 节点做配置变更;
-
ApplyConfChange:在配置变更提议在 raft 内已提交之后,向算法层发布配置变更内容,使变更立即生效;
-
ReadIndex:应用层向算法层发起读数据请求;
-
Step:向算法层传送一条任意类型消息;
-
Ready和Advance:获取 Ready channel 给应用层监听,当读取到 ready 信号时表明算法层已产生了新一轮的处理结果,应用层进行响应;处理完后调用 advance 方法向算法层表示应用层已处理完毕,进入下一轮。
接下来是剩下的和 raft 算法有关的数据结构。
type Progress struct {
Match, Next uint64
}
progress 是 leader 用于记录其他节点日志同步进度的结构,对应论文的 matchIndex 数组 和 nextIndex 数组。
type raft struct {
id uint64
// 任期号
Term uint64
// 投票给哪个节点ID
Vote uint64
raftLog *raftLog
prs map[uint64]*Progress
state StateType
// 该map存放哪些节点投票给了本节点
votes map[uint64]bool
msgs []pb.Message
lead uint64
// 标识当前还有没有applied的配置数据
pendingConf bool
readOnly *readOnly
electionElapsed int
heartbeatElapsed int
preVote bool
heartbeatTimeout int
electionTimeout int
randomizedElectionTimeout int
// tick函数,在到期的时候调用,不同的角色该函数不同
tick func()
step stepFunc
}
raft 结构是 raft 节点的总体抽象,和论文中对应,包含当前节点id、term、state 等等,随机的选举间隔等等也可以在这里找到。
应用层数据结构
下面根据 etcd 提供的 raft 运行示例的设计作为参考,看一下应用层的数据结构,如何维护与算法层的交互、状态机和 http 接口等等。
raftNode 是应用层对 raft 节点的封装,除了算法层的入口,还有与客户端、状态机、持久化相关的结构:
type raftNode struct {
proposeC <-chan string // proposed messages (k,v)
confChangeC <-chan raftpb.ConfChange // proposed cluster config changes
commitC chan<- *string // entries committed to log (k,v)
// ...
id int // client ID for raft session
peers []string // raft peer URLs
// ...
appliedIndex uint64
// raft backing for the commit/error channel
node raft.Node
raftStorage *raft.MemoryStorage
// ...
transport *rafthttp.Transport
// ...
}
- 三个 channel 分别是接收客户端的写请求、配置变更请求,以及将已提交的日志应用到状态机;
- 保留有 peers、appendIndex、node(上面说的算法层入口)等与算法层相关的信息;
- raftStorage 持久化日志的存储模块;
- transport 网络通信模块。
kvstore 是 example 实现的简易版k-v存储模块,用来模拟 etcd 的 kv 和 raft 节点的交互:
type kvstore struct {
proposeC chan<- string // channel for proposing updates
mu sync.RWMutex
kvStore map[string]string // current committed key-value pairs
}
其中 proposeC 是和 raftNode 同一个的 channel,负责向 raftNode 发来自客户端的写请求。
在 kvstore 模块启动时,会注入一个 commitC channel,kvstore 会持续监听它,收到 raftNode 提交的日志后将其应用到状态机(map)。
另外 example 还实现了一个简单的 http api,通过 PUT 表示写请求,POST 表示添加节点的配置变更请求,DELETE 表示删除节点的配置变更请求。
应用层与算法层的交互流程
应用层运行
example 实现的简易版应用层中,startRaft 方法包含了应用层和算法层的初始化和启动过程:
func (rc *raftNode) startRaft() {
// ...
rpeers := make([]raft.Peer, len(rc.peers))
for i := range rpeers {
rpeers[i] = raft.Peer{ID: uint64(i + 1)}
}
c := &raft.Config{
ID: uint64(rc.id),
ElectionTick: 10,
HeartbeatTick: 1,
Storage: rc.raftStorage,
}
startPeers := rpeers
rc.node = raft.StartNode(c, startPeers)
// ...
rc.transport = &rafthttp.Transport{
ID: types.ID(rc.id),
ClusterID: 0x1000,
Raft: rc,
ServerStats: ss,
LeaderStats: stats.NewLeaderStats(strconv.Itoa(rc.id)),
ErrorC: make(chan error),
}
rc.transport.Start()
for i := range rc.peers {
if i+1 != rc.id {
rc.transport.AddPeer(types.ID(i+1), []string{rc.peers[i]})
}
}
go rc.serveRaft()
go rc.serveChannel
}
这个过程包含了获取其他 raft 节点的信息、创建 raft 节点配置、启动算法层 Node、启动通信模块、开启 raftNode 主循环(用于与算法层的 goroutine 联系)。
这个循环主要是干什么呢:
首先,启动新协程监听 proposeC 和 ConfChangeC 两个 channel 来接收客户端的 PUT 和配置变更请求,然后调用 Node 接口的 api将其发给算法层:
go func() {
// ...
for {
select {
case prop := <-rc.proposeC:
rc.node.Propose(context.TODO(), []byte(prop))
case cc, ok := <-rc.confChangeC:
cc.ID = confChangeCount
rc.node.ProposeConfChange(context.TODO(), cc)
}
}
// client closed channel; shutdown raft if not already
close(rc.stopc)
}
接下来,启动 tick 定时器,每个 tick 默认 100ms,定时调用 Node.Tick 方法驱动算法层执行定时函数:
ticker := time.NewTicker(100 * time.Millisecond)
defer ticker.Stop()
for{
select {
case <-ticker.C:
rc.node.Tick()
}
之后,raftNode 会通过上面提到的 node.Ready 接收算法层处理结果、用 node.Advance 进行响应;期间对待持久化的日志做持久化,调用通信模块发算法层要发的消息,与状态机交互并应用已提交的日志。
算法层运行
算法层的启动是从 StartNode 开始的:
func StartNode(c *Config, peers []Peer) Node {
r := newRaft(c)
// 初次启动以term为1来启动
r.becomeFollower(1, None)
for _, peer := range peers {
cc := pb.ConfChange{Type: pb.ConfChangeAddNode, NodeID: peer.ID, Context: peer.Context}
d, err := cc.Marshal()
if err != nil {
panic("unexpected marshal error")
}
e := pb.Entry{Type: pb.EntryConfChange, Term: 1, Index: r.raftLog.lastIndex() + 1, Data: d}
r.raftLog.append(e)
}
r.raftLog.committed = r.raftLog.lastIndex()
for _, peer := range peers {
r.addNode(peer.ID)
}
n := newNode()
go n.run(r)
return &n
}
这里的 becomeFollower 等等和自己实现的 raft 基本一致,就是做节点启动的初始化,和论文一样。
启动之初,会把集群中的其他节点封装成配置变更信息,添加到非持久化日志里,并且视为已提交。
之后,异步调用 node.Run 方法,启动算法层 goroutine:
func (n *node) run(r *raft) {
var propc chan pb.Message
var readyc chan Ready
var advancec chan struct{}
var prevLastUnstablei, prevLastUnstablet uint64
var havePrevLastUnstablei bool
var rd Ready
lead := None
prevSoftSt := r.softState()
prevHardSt := emptyState
for {
if advancec != nil {
// advance channel不为空,说明还在等应用调用Advance接口通知已经处理完毕了本次的ready数据
readyc = nil
} else {
rd = newReady(r, prevSoftSt, prevHardSt)
if rd.containsUpdates() {
// 如果这次ready消息有包含更新,那么ready channel就不为空
readyc = n.readyc
} else {
// 否则为空
readyc = nil
}
}
// ...
select {
case m := <-propc:
// 处理本地收到的提交值
m.From = r.id
r.Step(m)
case m := <-n.recvc:
// 处理其他节点发送过来的提交值
// filter out response message from unknown From.
if _, ok := r.prs[m.From]; ok || !IsResponseMsg(m.Type) {
// 需要确保节点在集群中或者不是应答类消息的情况下才进行处理
r.Step(m) // raft never returns an error
}
case cc := <-n.confc:
// 接收到配置发生变化的消息
if cc.NodeID == None {
// NodeId为空的情况,只需要直接返回当前的nodes就好
r.resetPendingConf()
select {
case n.confstatec <- pb.ConfState{Nodes: r.nodes()}:
case <-n.done:
}
break
}
switch cc.Type {
case pb.ConfChangeAddNode:
r.addNode(cc.NodeID)
case pb.ConfChangeRemoveNode:
// 如果删除的是本节点,停止提交
if cc.NodeID == r.id {
propc = nil
}
r.removeNode(cc.NodeID)
// ...
}
// ...
case <-n.tickc:
r.tick()
case readyc <- rd:
// 通过channel写入ready数据
// 以下先把ready的值保存下来,等待下一次循环使用,或者当advance调用完毕之后用于修改raftLog的
if rd.SoftState != nil {
prevSoftSt = rd.SoftState
}
if len(rd.Entries) > 0 {
// 保存上一次还未持久化的entries的index、term
prevLastUnstablei = rd.Entries[len(rd.Entries)-1].Index
prevLastUnstablet = rd.Entries[len(rd.Entries)-1].Term
havePrevLastUnstablei = true
}
if !IsEmptyHardState(rd.HardState) {
prevHardSt = rd.HardState
}
// ...
r.msgs = nil
r.readStates = nil
// 修改advance channel不为空,等待接收advance消息
advancec = n.advancec
case <-advancec:
// 收到advance channel的消息
if prevHardSt.Commit != 0 {
// 将committed的消息applied
r.raftLog.appliedTo(prevHardSt.Commit)
}
advancec = nil
// ...
}
}
这里用了一大组 select,还有嵌套,主要是为了确保 ready 和 advance 两个方法是成对调用的,且算法层没有新结果产生时不会向应用层提交 ready 消息。