
linux CFS 调度器及应用扩展
简介
CFS 完全公平调度器是 linux 处理普通任务的默认调度器。其主要理念是完全公平理想模型,即有 n 个任务,那么每个调度周期内每个任务都应当获得 1/n 的运行时间。考虑到权重,实际每个任务运行的时间会乘上权重(自己的权重/全局权重和)。
实现上,CFS通过红黑树来维护当前调度周期内每个任务(考虑了权重)的当前已运行时间,为了使调度公平接近理想模型,每次调度时取红黑树最左侧也就是当前(考虑了权重的)已运行时间最少的任务出来运行,下次调度时将其运行的时间加上,返回红黑树重新取最左侧的任务。这样就能尽量公平(且考虑权重)地分配时间。
概念
调度周期:每次进行公平划分的时间间隔,将所有处于 running 状态的进程都调度一遍的时间(换句话说,所有进程在考虑权重后平分调度周期)。在每个调度周期中,每个任务都尽可能分到同样多的 vruntime。这个调度周期主要影响到任务切换的频率,每种任务的运行间隔最多为一个调度周期。调度周期的值一般情况是固定配置的 sched_latency_ns。每个进程每次的理想运行时间是 调度周期 * (当前进程权重/全部进程权重和)
调度粒度:sched_min_granularity_ns,作为 vruntime 的最小时间单位。调度粒度取值主要受核数影响,在调度粒度内进程不能被抢占,保证不会过于频繁触发任务切换。
vruntime:虚拟运行时间。vruntime = vruntime + delta_exec * nice / nice0,其中delta_exec是进程在 cpu 上实际运行的时间增量,nice与当前进程权重成反比,nice0是nice基准值。也就是说 vruntime 的增长倍率和权重负相关,权重越高 vruntime 增长越慢。
细节
运行步骤
任务被创建或唤醒时,进入就绪队列,它是一棵红黑树,每个节点保存了一个进程的 vruntime,从而维护全局最小的 vruntime。CFS调度器通过时钟中断来触发 tick,检查当前运行的任务和红黑树维护的最小 vruntime,判断是否需要切换。如果有更低 vruntime 的任务,就会发生任务切换。
动态时间片
cfs 中的时间片是动态的,由于一个调度周期内必须运行所有进程,如果负载提高,每个进程在周期内被分配的时间片都会减少。这样时间片就变成了相对的概念,一秒内进程切换的次数就不再和进程优先值有关了,只和调度周期与进程数量有关。
调度周期一般是固定值 sched_latency_ns,由于在调度周期内要确保所有进程都得到执行,且每个进程执行的最少时间不低于调度粒度 sched_min_granularity_ns,所以如果负载过高导致 sched_latency_ns / 进程数 < 调度粒度,调度周期就会自动变成 sched_latency_ns * 进程数量,保证任何情况下不会有进程饿死。
进程权重
进程权重通过一个称为 nice 值的机制控制,nice 值取值 -20-19,默认值为0,nice值越小权重越大。nice 值通过一个指数函数映射到权重,具体来说是 weight = 1024 / (1.25 ^ nice),nice值增大则权重指数式降低。nice 值可以通过 nice 命令设置或管理员通过 renice 命令修改。
扩展
cgroup 的 cpu 管理
在 cgroup 中,定义了两个新概念,把它们配合使用就可以控制一定时间内一个进程的 cpu 时间 quota:
$ cat cpu.cfs_quota_us
50000
$ cat cpu.cfs_period_us
100000
其中,我们把 cpu.cfs_period_us 叫做一个重分配周期,在每个重分配周期中,可以经过多个 cfs 调度周期,但该进程的 cpu 时间加起来不能超过 cpu.cfs_quota_us。例如上面的这组,意思是每 100 ms 一个周期,其中该进程最多占用 cpu 50 ms,超过了就会被限流,即使 cpu 空闲也不会调度它。类似下面这样:
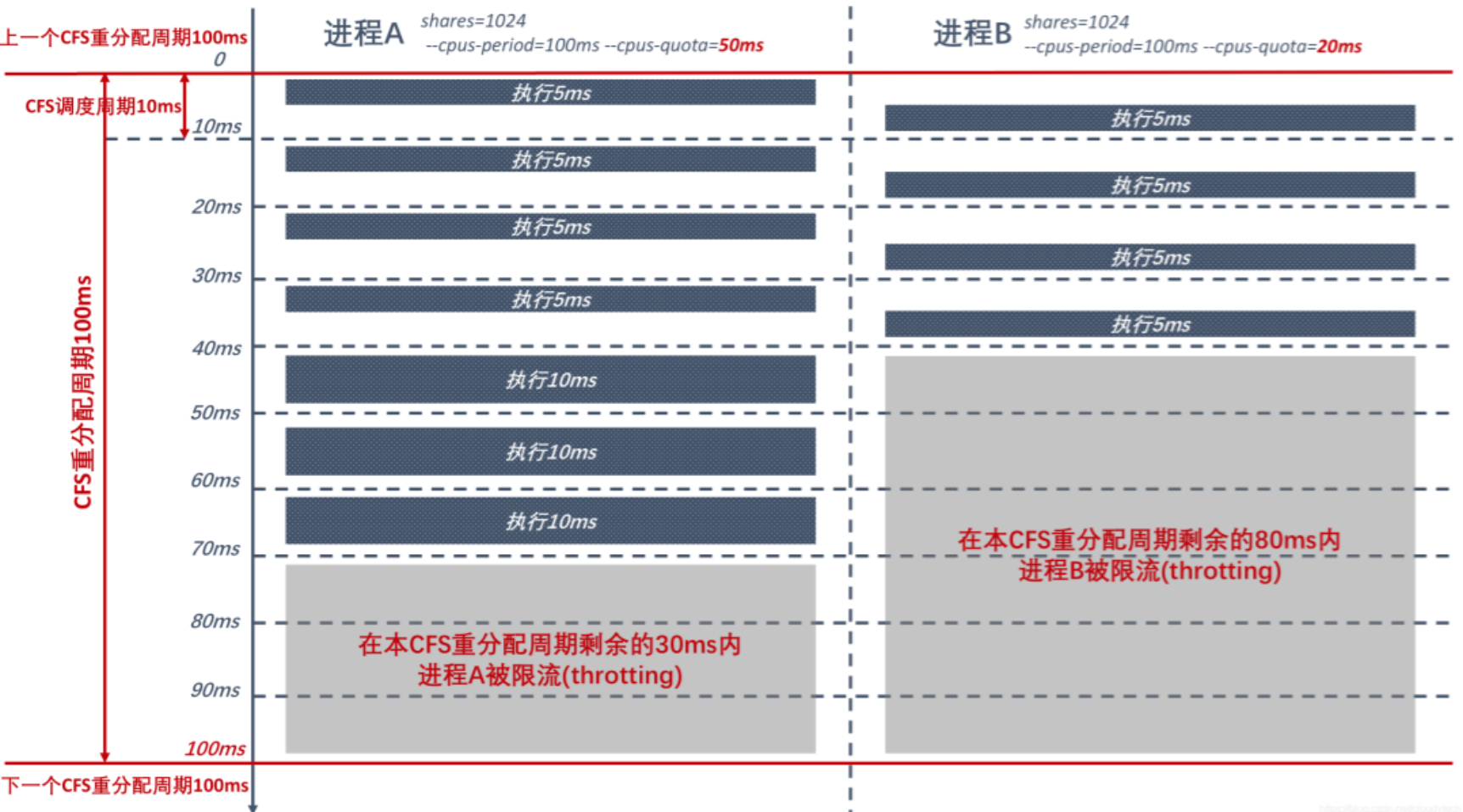
注意这个 quota 值是考虑了多核的,最大可以设置为核数*重分配周期,最小为 1ms。
从上面的原理,可以容易得出, cpu.cfs_quota_us / cpu.cfs_period_us 实际上就是整体来看这个进程能使用的核数。例如如果将 quota 设到最大值,那么就认为这个进程的最大核数为物理核数。因此常用这个特性来对进程/容器的核数做限制,就是我们说的x核xG的那个意思。需要留意,这里的限流即使 cpu 是完全空闲的也会生效,可能导致 cpu 浪费,所以不要随意设置。
除了这个 quota 限制,cgroup 还会控制在不同的 cgroup 之间,需要竞争 cpu 时分得的时间比例:
- 引入 cpu.shares 参数(默认 1024),表示在 cgroup 间竞争时,该 cgroup 能获得
1024/(竞争的cgroup的cpu share 总和)的时间 - 按 cgroup 的时间划分发生在 cfs 按权重调度之前。也就是说在每个 cfs调度周期(sched_latency_ns)中,如果启用了 cgroup,会先根据 cpu share 将调度周期的时间按比例分配,然后再在每个 cgroup 组内的份额中运行 cfs 算法,按进程权重进行调度。
- cpu share 只在资源紧张时(有多个 cgroup 的进程竞争一个 cpu 时)生效,如果资源不紧张,单个cgroup中的进程能独占一个 cpu 时,即使其 cpu share 很小,也可以独占 cpu。
k8s 中的 cpu limit
k8s 中的 pod 可以通过声明 resource request 的方法来限制容器的 cpu 使用,其实本质用到的就是上述的 docker -> cgroup 的 cpu.cfs_quota_us / cpu.cfs_period_us 的功能,例如:
resources:
requests:
cpu: "500m" # 请求 0.5 个 CPU 核
limits:
cpu: "1" # 限制使用最多 1 个 CPU 核
其中 500m 就是 0.5 个核,这里 m 指的是 millicores 毫核。实际上就是通过控制容器进程的 cpu.cfs_quota_us,利用 cgroup 进行 cpu 资源限流。
在 k8s 中,如果不设置 limit 或设置过高,可能导致单个容器耗尽 cpu 资源导致整个节点都不可用;而设置过低会引起不必要的资源浪费和程序延迟。所以一般来说,将这个 limit 设置为观测 cpu 用量的 P95 值左右比较好。社区也在讨论其他方法解决 limit 设置导致的不必要的性能问题。