
CubeCache 实现笔记

CubeCache是原先计划为 CubeUniverse 实现的分布式一致性缓存组件,旨在实现 CubeUniverse 系统缓存空间的线性可扩展。原计划该组件直接利用 redis 实现,但最近看到7daysgolang和godis的内存数据库实现,又产生了造轮子的冲动,决定我也来一个。
#0x00 背景
为什么需要缓存?不管是什么样的架构,但凡涉及瓶颈与性能分析,缓存肯定是非常重要的技术设计。对于单机数据库,在面临海量请求压力,包括数据存储本身和对应的计算(如排名)等,我们是不可能每次都让请求打入数据库的,毕竟数据库要保证ACID特性,需要牺牲性能,而且在持久化IO处是非常耗时、消耗性能的。如果我们能让大量请求不需要打入数据库,在内存解决问题,就可以极大地减轻性能压力。特别是对于 CubeUniverse 这样的面向大型分布式集群的系统,除去底层Ceph本身osd的CRUD,调度信息、平台服务层的元数据、机器学习任务元数据等如果均依赖高一致性持久化维护,就都要打入集群的不同节点的不同性能的存储设备处理请求,可能造成严重的性能瓶颈。
为什么需要分布式缓存?为什么不直接给operator加个map就当缓存了?显然地,这不符合系统的设计目标,也就是要求容量能随节点扩展而扩展,就单个机子的内存和性能肯定不够应付海量数据。其次,map本身是没有并发保护的,也不能简单的拿来直接当cache。此外,还需要严谨考虑锁设计以减少性能问题。
#0x01 技术设计
参考:memcached
memcached是一个开源、分布式的高性能内存缓存系统,是一个存储键值对的 HashMap,采用kv的方式在内存中保存任意数据。memcached 的架构示意图如下:
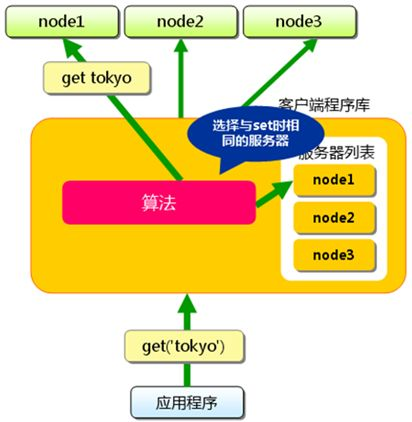
memcached 的设计逻辑是“小而美”,什么意思呢,通过分布式哈希算法,memcached 使得哈希过程在客户端即可完成,由客户端来选择具体去储存的节点,而非由集群自己协调,这样可以精致优雅地完成key在不同节点的分步。
不过,它的问题也比较明显,首先 memcached 把服务器选择完全在客户端这里实现,集群节点之间完全没有任何通信,可以说 memcached 并不是一个严格的分布式系统。这就导致客户端需要负责维护服务器列表,这就给服务器节点的可扩展性和灵活性引入了困难。此外,memchached 几乎没有对容错的处理机制,虽然对缓存来说偶然的kv丢失不是什么问题,但如果在大量扩展下出现节点宕机的情况,由客户端去通过延时判断节点宕机再去调整服务器列表可能会出现严重的时延问题,反而违背了缓存的初衷了。
参考:Redis 缓存模式
redis 本身定位是一个内存kv数据库,但大多数应用实际上都是拿它做缓存,而且用的非常广泛。redis 的优化很好,支持的特性也多,市场占有量也是独角兽,可以说没什么不用它的理由了。但是仍然可以参考它的设计,尝试解决一些问题。
考虑 redis 的分布式设计。redis 提供了 cluster 模式,这种模式会组织一个去中心化的集群,这个平等集群中的每个单位又配置一主多从,在这个小群体里使用 Raft 算法来维护主,而从不提供服务。由于使用非中心化架构,redis 集群是不方便去维护一些共识信息的。我们可以考虑把我们的设计改为一个中心化架构,方便我们实现一些 redis 没法或者很难去实现的特性。
考虑 redis 的缓存模式。缓存一般有三种模式。cache aside 是最常用的,业务将缓存视为一个辅助组件,同时控制缓存和DB,这里就需要业务去决定缓存和DB的访问顺序、如何访问、是否访问等。并且这样也会引入潜在的缓存与DB不一致。事实上,redis 的一致性保证是最终一致性,也就是说缓存和DB会在一段时间内产生不一致,但一段时间后会归于一致。这也就意味着业务可能在 redis 集群读到过期数据。
除此之外缓存还有两种模式,但应用不多:Write-Through 和 Write-Back。它们都是业务直接访问缓存作为存储,由缓存而非业务来操作DB(cpu的缓存除外,概念不统一),区别在于 write-through 模式每次写时都应用到DB,而write-back 模式写时先同步修改到缓存,之后每隔一段时间统一应用到DB。显然这两种模式是一致性和效率的 trade-off。
考虑redis现存的一些问题。首先比较容易出现的是热key倾斜问题,由于缓存模式下短时间内某个或某些key对应的节点都是同一个单点,如果有短时突发大量针对这个key的流量进来容易导致单点问题。这个问题一般是由业务去解决的,但如果能在缓存平面解决,会更通用一些。
另外一个问题是可能会出现短时间大量的无效(key不存在)的get请求,这可能是恶意攻击或者业务程序错误导致的。这些恶意攻击通过伪造大量不存在key,短时间内穿透缓存造成业务被影响。打入布隆过滤器是一种以准确性换效率的过滤机制,可以以O(1)过滤掉一部分确定不在集合内的key,同时不引入太多的空间占用。在redis中没有自实现的布隆过滤器,一般由业务实现。我们可以做一个内置的过滤器作为优化。
综上,可以考虑利用中心化反向代理的优势,实现 redis 未实现的 Write-Through 和 Write-Back 模式,同时尝试去完成一些redis没有的优化。
架构设计
CubeCache缓存平台整体架构位于客户端(包含对应的sdk)和下层持久化平面(可以由关系型数据库、分布式存储系统、网络文件系统等构成,也可以抽象为其他持久化事务)之间,原则上运行于现代微服务架构中,称为缓存平面。客户端通过 CubeCache 提供的 sdk 简单调用 CubeCache 的服务,但由于 CubeCache 系统通信完全统一于 grpc 协议,客户端也可以通过 CubeCache 提供的 proto 定义自行组织 grpc 请求并按 CubeCache 协议要求修改 header 以实现自定义方法对服务端的访问。
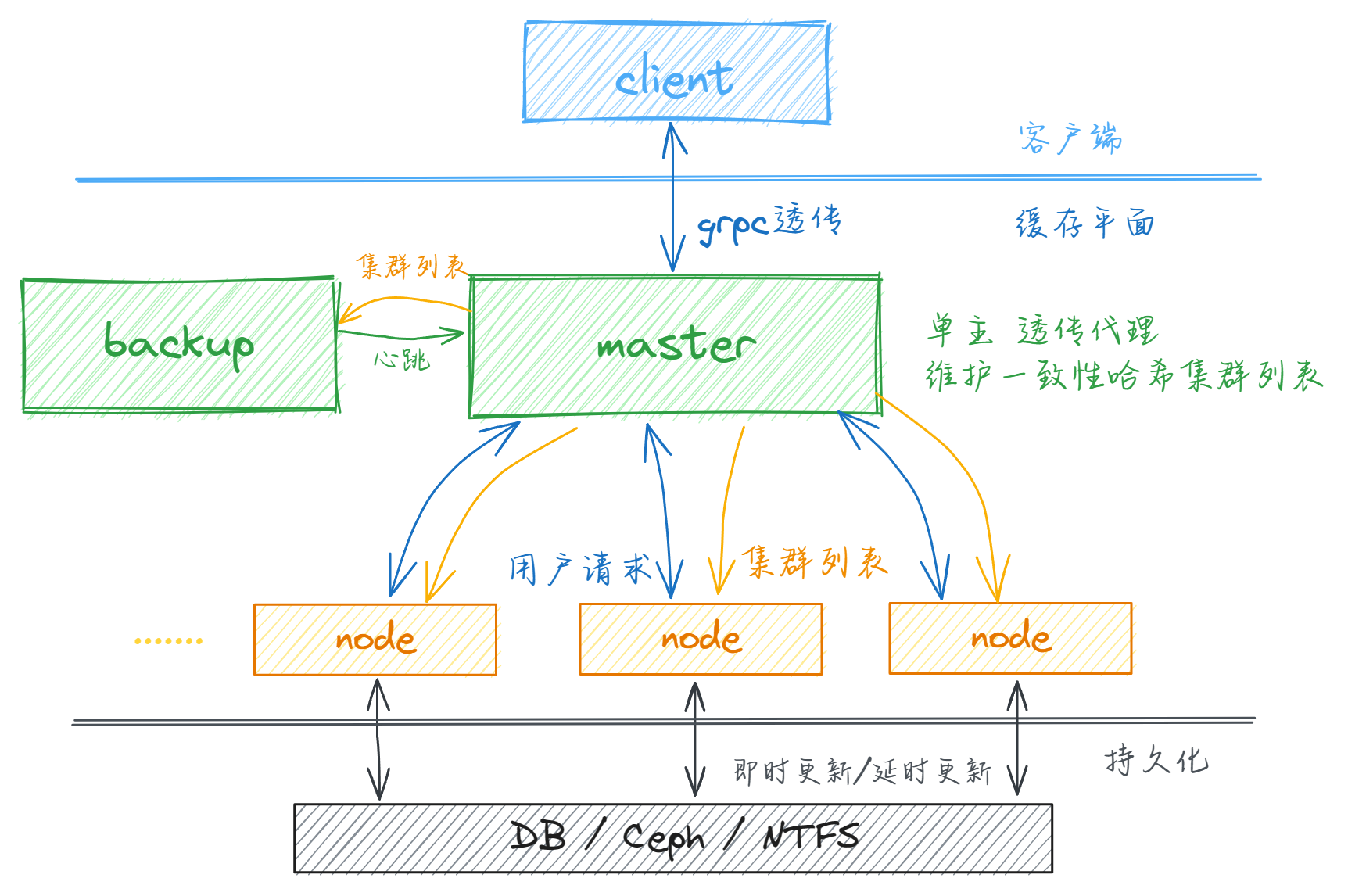
对于分布式可扩展性,基于上述对不同架构的考察和对简明性稳定性的考虑,CubeCache 将主要逻辑分为 master 和 node 两部分,其中 node 主要提供 Cube (分区与命名的k-v缓存)服务,相互独立、高可扩展,并在 master 相关协议中维护缓存数据的一致性;master 作为集群的中心控制节点,负责 grpc 流量的透传代理、一致性哈希算法的维护、节点服务注册与心跳维护、热key负载均衡等集群中心事务。在设计上,可扩展性主要体现在对 node 也就是k-v服务主体的可扩展性上。容易看出,经过中心化节点的集中维护,对于缓存来说,node 节点本身可被认为是无状态节点,因此可以方便地基于现代微服务基础设施进行大规模扩展和生命周期管理。而master 被设定为单点的、中心的服务,对其扩展以纵向扩展为主,即增加其单点机器的资源量。不对 master 节点做横向扩展设计,一是考虑到分布式系统设计简单性的重要性,中心节点维护整个分布式集群细节可以避免大量一致性相关的设计难点;二是可以避免类似 redis 所采取的高一致性要求所引起的冗余和网络流量代价,避免为维护低可能的非一致情况对微服务基础设施造成不必要的压力。纵向扩展后的 master 节点应当可以接受单个系统的缓存需求,如果有更高的连接数要求,分数并扩展到多个整套系统(master+node)应当是更合理更易于维护且更稳定的选择。
对于一致性,CubeCache 缓存平面对外提供专门针对缓存场景的分布式一致性,而舍弃面向k-v数据库场景的高一致性以换取高可扩展性和设计的简明性。CubeCache 保证在任何情况下,对于成功触发的 set 请求,只有顺利返回和缓存过期两种结果,保证不会读到过期数据或脏数据。相比 redis 等采用冗余的方法提供高强度的一致性,CubeCache 针对缓存场景通过中心化节点统一维护实现了0复制的容错机制,主要确保应用读取缓存不受脏数据问题影响。针对一致性问题的考虑,主要表现在 master 主从备份、master 维护的分布式哈希算法、节点切换时针对脏数据隐患的额外实现保证等。
#0x02 实现单机LRU
先从简单的东西开始实现。我们的目标是实现一个分布式的、可随节点扩容而扩展的缓存。实际上我们所说的缓存就是一个kv数据库,考虑到缓存不需要严格高可用,而且内存资源宝贵,不可能像mysql主从架构一样奢侈,所以我们只需要想办法把让kv均匀分布在多个节点上即可。很容易想到,我们可以实现一个分布式的hashMap,想办法让分布均匀就好。
作为缓存,我们首先实现一版单机的LRU,使得内存使用超限时能自动淘汰部分数据。此时先不考虑并发问题。
LRU在go里的一个简单的实现方式是一个map+一个linkedlist(container库里的list),list储存具体的kv对,map映射k和对应list_node。每次put或者get一个kv就把那个节点往队尾放,淘汰的时候取队首删除即可。
结构定义:
import "container/list"
type Cache struct {
maxBytes int64
nowBytes int64
cache map[string]*list.Element
innerList *list.List
OnEvicted func(key string, value CacheValue)
}
type CacheEntry struct {
key string
value CacheValue
}
type CacheValue interface {
Len() int
}
其中Cache补充了最大字节限制、当前字节占用(通过k、v的len计算)、回调函数(删除一个kv时调用)。这里直接使用container标准库里的链表来替代手动实现,其中list.Element是链表的节点定义,后面使用cache内部字段的时候要记得用反射转成CacheEntry。
之后就是完成对应的功能方法:
func New(maxBytes int64, onEvicted func(key string, value CacheValue)) *Cache {
return &Cache{
maxBytes: maxBytes,
cache: make(map[string]*list.Element),
innerList: list.New(),
OnEvicted: onEvicted,
}
}
func (c *Cache) Get(key string) (value CacheValue, ok bool) {
v, ok := c.cache[key]
if ok {
c.innerList.MoveToBack(v)
return v.Value.(*CacheEntry).value, true
}
return nil, false
}
func (c *Cache) EliminateOldNode() {
old := c.innerList.Front()
if old == nil {
return
}
c.innerList.Remove(old)
oldEntry := old.Value.(*CacheEntry)
delete(c.cache, oldEntry.key)
c.nowBytes -= int64(len(oldEntry.key)) + int64(oldEntry.value.Len())
if c.OnEvicted != nil {
c.OnEvicted(oldEntry.key, oldEntry.value)
}
}
func (c *Cache) Set(key string, value CacheValue) {
element, ok := c.cache[key]
if ok {
c.innerList.MoveToBack(element)
entry := element.Value.(*CacheEntry)
c.nowBytes = c.nowBytes - int64(entry.value.Len()) + int64(value.Len())
entry.value = value
} else {
element = c.innerList.PushBack(&CacheEntry{
key: key,
value: value,
})
c.cache[key] = element
c.nowBytes += int64(len(key)) + int64(value.Len())
}
for c.maxBytes != -1 && c.innerList.Len() > 0 && c.nowBytes > c.maxBytes {
c.EliminateOldNode()
}
}
func (c *Cache) Len() int {
return c.innerList.Len()
}
实现的时候注意下细节即可。最好同步补一些UT确保无bug。
#0x03 实现单机并发缓存
缓存一定是要支持并发的,这样才能同时照顾多个线程的存取需要,同时保持较高的性能。7daysgolang的实现方法非常粗暴,加一个mutex就结束了,但实际上这样会导致并发的优势完全无法体现。所以这里参考godis,实现了一个分段锁的机制,定义新的数据结构Cube作为具名的缓存单机实例,包含若干个shard(也就是第一部分实现的lru缓存)以及每个shard对应的读写锁。此外Cube会存储一个getterFunc,由用户提供,为缓存未命中时用户指定的下层数据获取方法。
// Cube is a concurrency-safe cache instance with a name
type Cube struct {
shards []*lru.Cache
mu []sync.RWMutex
name string
// getterFunc is the custom func to call to get the target value
getterFunc func(key string) (value lru.CacheValue, err error)
}
func New(name string, getterFunc func(key string) (value lru.CacheValue, err error),
OnEvicted func(key string, value lru.CacheValue), maxBytes int64) *Cube {
cube := &Cube{
shards: make([]*lru.Cache, 32),
mu: make([]sync.RWMutex, 32),
name: name,
getterFunc: getterFunc,
}
for i := range cube.shards {
cube.shards[i] = lru.New(maxBytes/32, OnEvicted)
}
return cube
}
分段锁的机制实际上就是通过fnv之类的哈希算法,将key归类到不同的shard中,由于每个shard对应一个锁,读写一个shard就不影响其他shard,从而可以提高性能。
func GetShardId(key string) int {
fnv32 := fnv.New32()
_, err := fnv32.Write([]byte(key))
if err != nil {
println("err fnv32 hash:", err.Error())
return 0
}
return int(fnv32.Sum32()) % 32
}
func (c *Cube) Set(key string, value lru.CacheValue) {
shard := GetShardId(key)
c.mu[shard].Lock()
defer c.mu[shard].Unlock()
c.shards[shard].Set(key, value)
}
func (c *Cube) Get(key string) (value lru.CacheValue, ok bool) {
shard := GetShardId(key)
c.mu[shard].RLock()
defer c.mu[shard].RUnlock()
value, ok = c.shards[shard].Get(key)
// Cache do not have that record. Get by user func
if !ok && c.getterFunc != nil {
valueOutsideCache, err := c.getterFunc(key)
if err == nil {
value = valueOutsideCache
ok = true
c.shards[shard].Set(key, value)
}
}
return value, ok
}
由于我们实现的是分布式缓存而不是数据库,所以不需要支持遍历和持久化等,设计起来比较简单。
#0x04 实现接入http
系统在设计上除了作为一个单机缓存包被代码引入使用,还应当作为一个单独的分布式中间件被使用,并作彼此之间的沟通协调。这里使用gin框架来完成一个简单的http接入。
func initRouter() *gin.Engine {
r := gin.Default()
r.GET("/cube/:subPath", handleGet)
r.POST("/cube/:subPath", handlePost)
return r
}
处理get和post请求:
func handleGet(ctx *gin.Context) {
cubeName := ctx.Param("subPath")
cube, ok := cubeCache.Cubes[cubeName]
if !ok {
ctx.JSON(400, gin.H{"msg": "cube " + cubeName + " not found"})
return
}
key := ctx.Param("key")
byteValue, ok := cube.Get(key)
if !ok {
ctx.JSON(401, gin.H{"msg": "user getter func for " + cubeName + "/" + key + " error"})
return
}
bytes := byteValue.(*lru.Bytes)
ctx.Data(200, "application/octet-stream", bytes.B)
}
func handlePost(ctx *gin.Context) {
cubeName := ctx.Param("subPath")
cube, ok := cubeCache.Cubes[cubeName]
if !ok {
ctx.JSON(400, gin.H{"msg": "cube " + cubeName + " not found"})
return
}
key := ctx.Param("key")
body, err := io.ReadAll(ctx.Request.Body)
if err != nil {
ctx.JSON(400, gin.H{"msg": "read request body fail"})
return
}
byteValue := &lru.Bytes{B: body}
cube.Set(key, byteValue)
ctx.JSON(200, gin.H{"msg": "success"})
}
这里将subPath作为一个参数传递给处理函数,实际上对应的是请求url的最后一个子目录,也就是我们的cube名称。在Post和Get的时候缓存value都以二进制(byte数组)形式存放在body中,参数通过param传递。
#0x05 实现一致性哈希
下面就实现面向分布式的第一步:一致性哈希。
为什么需要一致性哈希?我们在设计分布式缓存的时候,就需要尽可能保证对于每个key,我们都只让其对应唯一一个节点,避免反复在不同节点拉取数据占用多倍的时间和空间。
一个最理想情况下的方法就是给节点编个号,使用哈希算法把key散布到不同节点。然而对于一个集群,往往涉及节点的动态变化,直接使用哈希来映射key和节点编号,可能导致一旦集群出现细微增删,所有映射就全部失效,导致目前已在本地的所有数据全部无效,致使瞬时DB请求大导致雪崩,这对于缓存来说是不可接受的。
一致性哈希算法解决的问题就是对key在动态节点变化下的散布问题。它的解决方法有点类似时间轮算法,引入一个环,将节点散布在环上,再将key散布到环上。每个key对应的节点就是沿环顺时针找到的第一个节点。这样,在产生节点变动时,影响到的key就只有该节点到前一个节点之间的部分,而非全部。
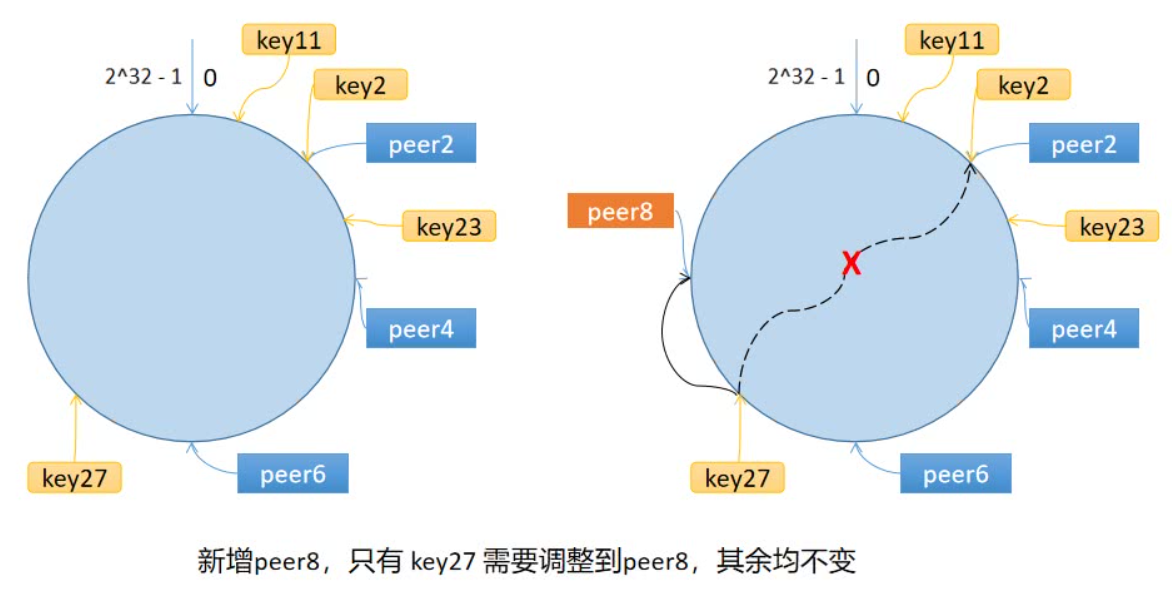
当然,考虑到节点相对于环的分布是随机散列的,可能会产生数据不平衡的问题,这里可以通过引入虚拟节点的方式来解决。我们为每个物理节点都设置若干个虚拟节点,再将这些虚拟节点散列在环上,同时维护一个虚拟节点与物理节点之间的映射。这样,通过增加了节点的数量,我们就以很小的代价解决了数据倾斜的问题。
具体代码实现上,我们引入一个mapper作为维护哈希环的数据结构,提供AddNode、RemoveNode和Get方法来为CubeCache提供key-node的映射服务:
// Mapper maintains consistency-hash wheel for all nodes
type Mapper struct {
// number of replicated nodes on the wheel
replicaNum int
// nodes keeps the wheel of hashed nodeName, sorted
nodes []int
mapNodesName map[int]string
mu sync.RWMutex
}
func NewMapper(replicaNum int) *Mapper {
return &Mapper{mapNodesName: make(map[int]string), replicaNum: replicaNum}
}
// AddNode add a node to the wheel
func (m *Mapper) AddNode(nodes ...string) {
m.mu.Lock()
defer m.mu.Unlock()
for _, v := range nodes {
for i := 1; i <= m.replicaNum; i++ {
hash := int(crc32.ChecksumIEEE([]byte(strconv.Itoa(i) + v)))
m.nodes = append(m.nodes, hash)
m.mapNodesName[hash] = v
}
}
sort.Ints(m.nodes)
}
// RemoveNode remove a node from the wheel
func (m *Mapper) RemoveNode(node string) {
m.mu.Lock()
defer m.mu.Unlock()
for i := 1; i <= m.replicaNum; i++ {
hash := int(crc32.ChecksumIEEE([]byte(strconv.Itoa(i) + node)))
index := sort.SearchInts(m.nodes, hash)
if index < len(m.nodes) && m.nodes[index] == hash {
m.nodes = append(m.nodes[:index], m.nodes[index+1:]...)
delete(m.mapNodesName, hash)
}
}
}
// Get the node to visit
func (m *Mapper) Get(key string) (node string) {
m.mu.RLock()
defer m.mu.RUnlock()
if len(m.nodes) == 0 {
return ""
}
hash := int(crc32.ChecksumIEEE([]byte(key)))
idx := sort.SearchInts(m.nodes, hash)
if idx >= len(m.nodes) {
idx = 0
}
return m.mapNodesName[m.nodes[idx]]
}
我们使用数组nodes来表示哈希环,使用sort库排序保持其始终递增。在Get时使用sort.SearchInts,这是自带的二分查找方法,来取得key对应的node。
#0x06 实现分布式特性准备
为减小设计难度起见,上述的实现都是由单个组件开始扩展,配合UT逐步实现其对应的独立功能。实现至此,下一步我们需要对已经实现的部分做一些修改,以为整套系统组合和实现分布式特性做准备。
首先是针对单机 Cache 和 Cube 的修改。集群的一致性维护和合理需求要求缓存需要设计一个超时时间,在这个超时时间后 value 应被过期并自动清除。这个超时时间也决定了 master 对一致性保证的支持时间和对应维护数据的保存时间。
作为前期准备,由于 Timestamp 需要以 proto 支持的数据类型在节点之间传递,我们在 util 包上实现一个包装类负责 time 包的 timestamp 和数值类型时间的转换:
type Timestamp struct {
Second int64 // unix second
NanoSecond int64 // nanoSecond left
}
func (t *Timestamp) Time() time.Time {
return time.Unix(t.Second, t.NanoSecond)
}
func NewTimestamp(second int64, nanoSecond int64) *Timestamp {
return &Timestamp{
Second: second,
NanoSecond: nanoSecond,
}
}
func NewTimestampForNow() *Timestamp {
return &Timestamp{
Second: time.Now().Unix(),
NanoSecond: int64(time.Now().Nanosecond()),
}
}
由于 Cube 是 Cache Shard 的集合,我们需要单独对每个 shard 维护一个 goroutine 负责定时清理过期数据:
func (c *Cube) cleanExpireNode(shard int) {
for {
time.Sleep(config.ExpireCleanInterval)
c.mu[shard].Lock()
func() {
defer c.mu[shard].Unlock()
c.shards[shard].DeleteAllExpiredNode()
}()
}
}
在每个 shard 的实现中,为 CacheValue 增加 timestamp 字段,以此实现清理过期数据的方法供 cube 调用。
除此之外,master 对于节点更替的一致性维护需要一种数据结构来维护节点变更时受影响的区间,并满足快速判断一个值是否在这些海量区间范围内。由于节点更替可以很频繁,这些区间数量可能很多,我们的数据结构需要能够在O(lgN)的复杂度完成对值相对于区间的判定。
区间树是一种红黑树的扩展,其每个节点的值维护的是区间,它可以支持以区间为元素的动态集合的操作,可以使区间的元素查找插入都以log的复杂度完成。将区间树在 util 包内实现并做好封装,供后期使用:
// 定义区间结构体
type Interval struct {
Start int
End int
}
// 定义区间树结构体
type IntervalTree struct {
root *intervalNode
}
// 定义区间树节点结构体
type intervalNode struct {
interval Interval
maxEndInSubtree int
left *intervalNode
right *intervalNode
}
// 创建一个区间树节点
func newIntervalNode(interval Interval) *intervalNode {
return &intervalNode{
interval: interval,
maxEndInSubtree: interval.End,
left: nil,
right: nil,
}
}
// 区间树插入操作
func (t *IntervalTree) Insert(interval Interval) {
t.root = t.insertNode(t.root, interval)
}
// 递归插入节点
func (t *IntervalTree) insertNode(node *intervalNode, interval Interval) *intervalNode {
if node == nil {
return newIntervalNode(interval)
}
if interval.Start < node.interval.Start {
node.left = t.insertNode(node.left, interval)
} else {
node.right = t.insertNode(node.right, interval)
}
if node.maxEndInSubtree < interval.End {
node.maxEndInSubtree = interval.End
}
return node
}
// 区间树删除操作
func (t *IntervalTree) Delete(interval Interval) {
t.root = t.deleteNode(t.root, interval)
}
// 递归删除节点
func (t *IntervalTree) deleteNode(node *intervalNode, interval Interval) *intervalNode {
if node == nil {
return nil
}
if interval.Start < node.interval.Start {
node.left = t.deleteNode(node.left, interval)
} else if interval.Start > node.interval.Start {
node.right = t.deleteNode(node.right, interval)
} else {
if interval.End == node.interval.End {
// 删除节点
if node.left == nil {
return node.right
} else if node.right == nil {
return node.left
} else {
// 找到右子树最小节点
minNode := t.findMinNode(node.right)
node.interval.Start = minNode.interval.Start
node.interval.End = minNode.interval.End
node.right = t.deleteNode(node.right, Interval{Start: minNode.interval.Start, End: minNode.interval.End})
}
} else {
node.right = t.deleteNode(node.right, interval)
}
}
if node != nil {
if node.right != nil && node.right.maxEndInSubtree > node.maxEndInSubtree {
node.maxEndInSubtree = node.right.maxEndInSubtree
} else if node.left != nil && node.left.maxEndInSubtree > node.maxEndInSubtree {
node.maxEndInSubtree = node.left.maxEndInSubtree
}
}
return node
}
// 找到区间树中的最小节点
func (t *IntervalTree) findMinNode(node *intervalNode) *intervalNode {
if node.left == nil {
return node
}
return t.findMinNode(node.left)
}
// 判断一个数是否在区间树内
func (t *IntervalTree) IsNumberInIntervals(number int) bool {
return t.isNumberInIntervals(t.root, number)
}
// 递归判断数值是否在区间内
func (t *IntervalTree) isNumberInIntervals(node *intervalNode, number int) bool {
if node == nil {
return false
}
if number >= node.interval.Start && number <= node.interval.End {
return true
} else if node.left != nil && number <= node.left.maxEndInSubtree {
return t.isNumberInIntervals(node.left, number)
} else {
return t.isNumberInIntervals(node.right, number)
}
}
#0x07 rpc 接口设计实现
grpc 通过 protobuf 来实现跨语言的数据定义,然后通过 protobuf 的序列化能力进行序列化,实现 rpc 的相关功能。我们为 cube 服务定义 rpc 接口设计如下:
option go_package = "cubeCache/rpc";
message SetValueRequest {
string cubeName = 1;
bytes value = 3;
optional string getterFunc = 4; // optional getter lua script for specified key
}
message SetValueResponse {
}
message GetValueRequest {
string cubeName = 1;
}
message GetValueResponse {
bool ok = 1;
bytes value = 2;
string message = 3;
}
message CreateCubeRequest{
string cubeName = 1;
int64 maxBytes = 2;
optional string cubeInitFunc = 3;
optional string cubeGetterFunc = 4; // optional default getter lua script for the cube
optional string onEvictedFunc = 5; // optional call-back lua script when key is evicted
optional bool delayWrite = 6; // use write-delay mode
}
message CreateCubeResponse{
bool success = 1;
string message = 2;
}
service Cube {
rpc Get(GetValueRequest) returns (GetValueResponse);
rpc Set(SetValueRequest) returns (SetValueResponse);
}
service CubeControl{
rpc CreateCube(CreateCubeRequest) returns(CreateCubeResponse);
}
可以发现我们没有在 rpc request 中传递 key。设计上,我们将 key 作为 grpc 的 context(体现到传输协议上就是 http2 的 header),这样便于 master 的七层代理预先判定目标。除此之外,我们把创建 cube 作为 master 独有的功能放在 CubeControl service 中。
接下来就是对节点注册/集群管理功能的接口设计:
option go_package = "cubeCache/cluster";
import "protobuf/cube.proto";
message RegisterNodeRequest{
string address = 1;
}
message RegisterNodeResponse{
bool success = 1;
repeated CreateCubeRequest cubes = 2;
}
message SendHeartbeatRequest{
string address = 1; // address with cube-service port
int32 cubeWeight = 2; // to verify cube consistency
}
message SendHeartbeatResponse{
bool inconsistent = 1; // cube inconsistent with master or heartbeat lost, re-register needed
}
service Cluster{
rpc RegisterNode(RegisterNodeRequest) returns(RegisterNodeResponse);
rpc SendHeartbeat(SendHeartbeatRequest) returns(SendHeartbeatResponse);
}
这里包含了节点注册、心跳机制、cube 列表同步机制等内容。可以看到我们对潜在脏数据的同步机制并不体现在这里,因为这层同步是基于七层代理完成,主要依靠 http header 来完成对应的通信。
#0x08 grpc 反向代理实现
架构设计时,我们将分布式哈希算法全权委托在 master 上完成,就意味着我们需要在 master 实现一个七层的反向代理,解析 key 并执行一致性哈希获取目标,然后对 grpc 请求进行透传。具体来说,我们需要一种方法让 master 能够接收请求时提前获取一部分头部信息,选择出 node,然后把整个请求透传到另一个对 node 的 grpc 连接上。
grpc 实现是基于 http2 的,因此第一种实现方法就是去实现一个基于 http2 的反向代理,这样也就同时完成了对 grpc 的代理。于是第一个实现方案就是通过 golang 的 http 库完成了一套针对 http2 及其请求头的反向代理,测试其可以代理正常的 https 请求。
然而,经过测试发现 grpc 服务器在处理被代理的请求会产生 502 报错。抓包研究,发现 grpc 在发信时会在 header 中保留两个关于 path 的字段,使用默认方法修改 path 会导致服务器报错。因此只能采用更 grpc 原生的方法,采用 grpc-proxy 库,这是一种利用 grpc 的 unknownServiceHandler 机制的 grpc 代理,可以利用 grpc 原生提供的 Dial 和 Context metadata,这样就可以避免 grpc 在实现上的 trick 影响代理的正常工作了。
于是,我们只用和实现正常的 rpc 客户端/服务端一样实现支持证书和连接的代码,然后通过 director 函数,利用 context (对应http2的header)来选择 node、建立新的 grpc 连接并实现透传:
func director(ctx context.Context, fullMethodName string) (context.Context, *grpc.ClientConn, error) {
md, _ := metadata.FromIncomingContext(ctx)
keys, ok := md["cube_cache_key"]
if !ok || len(keys) != 1 {
return nil, nil, errors.New("cube proxy error: no cube_cache_key header")
}
target := server.mapper.Get(keys[0])
outCtx := metadata.NewOutgoingContext(ctx, md)
conn, err := grpc.DialContext(outCtx, target, grpc.WithCodec(proxy.Codec()), grpc.WithTransportCredentials(transportCredits))
if err != nil {
return nil, nil, err
}
return outCtx, conn, nil
}
#0x09 通过 lua 虚拟机支持 write-through 模式
Lua 是一种轻量小巧的动态脚本语言,可以嵌入程序中提供灵活的扩展和定制功能,并且性能相对 python 还算不错,在 redis 中也会用 lua 来完成一些高级支持。CubeCache 中,如果用户选择使用 write-through 或 write-back 模式,lua 脚本将作为缓存平面和下层持久化层交互的方法,允许用户动态地定义交互的具体细节,以实现极高的灵活性。通过采用 lua 动态定义的交互模式,用户不仅可以为 cache 绑定传统关系型数据库,也可以绑定分布式存储、网络文件系统,甚至是对其他系统通过中间件发来的信息进行消费(消息队列等)。
gopher-lua 是一种在 golang 内实现调用 lua 虚拟机的实现,并且它支持以 LState 的形式传递 lua 虚拟机的状态,这为我们在缓存与持久层交互的多种逻辑提供方便。一般而言,对持久层(也可以抽象地换作其他系统)的操作包括初始化(初始化数据库/ceph连接等)、写数据(set)、读数据(get)三种。CubeCache 将在对应时间点调用用户的 lua 脚本并传递必要信息,用户则根据约定编写 lua 函数并返回,完成对持久层的灵活访问,同时也扩大了持久层的定义,使缓存平面可以应用到更多广义的需要缓存的系统上来:
// RegisterLuaFunc register the lua script to LState
func RegisterLuaFunc(L *lua.LState, luaScript string) error {
if err := L.DoString(luaScript); err != nil {
return fmt.Errorf("register lua func error: %v", err)
}
return nil
}
func ExecuteSetterLua(L *lua.LState, key string, value []byte) error {
luaExecuteSetter := L.GetGlobal("setter")
if luaExecuteSetter == nil || L.GetTop() < 1 {
return fmt.Errorf("get lua setter func fail for key %s", key)
}
if err := L.CallByParam(lua.P{
Fn: luaExecuteSetter,
NRet: 1,
Protect: true,
},
lua.LString(key),
lua.LString(value),
); err != nil {
return fmt.Errorf("setter lua for key %s run fail: %v", key, err)
}
return nil
}
// ExecuteGetterLua execute query lua when key not in cache
func ExecuteGetterLua(L *lua.LState, funcName string, key string) ([]byte, error) {
// 获取查询函数
luaExecuteQuery := L.GetGlobal(funcName)
if luaExecuteQuery == nil || L.GetTop() < 1 {
return nil, fmt.Errorf("get lua getter func fail for key %s", key)
}
// 调用查询函数
if err := L.CallByParam(lua.P{
Fn: luaExecuteQuery,
NRet: 1,
Protect: true,
},
lua.LString(key),
); err != nil {
return nil, fmt.Errorf("查询执行失败: %v", err)
}
// 获取查询结果
luaQueryResult := L.Get(-1)
L.Pop(1)
// 转换为[]byte类型
queryResult := lua.LVAsString(luaQueryResult)
return []byte(queryResult), nil
}
这样,就支持了高度自定义的 write-through 和 write-back 模式。使用 CubeCache 的应用系统不需要再耗费额外精力维护缓存和持久层之间的关系,最大的好处是可以从原理上避免缓存穿透问题,还可以同时避免错误处理缓存和持久化的消息流顺序导致的不一致问题。这是 redis 所不具有的特性,对于 redis 来说,本身就不支持 write-through 或 write-back 模式,应用代码需要手动编写机制减少缓存穿透问题,这也是后端的常见问题之一。
#0x10 一致性保证与脏数据避免
对于很多基于分布式哈希算法的系统,比如 memcached,本身是不去维护节点一致性的,也不会考虑对可能的脏数据情景做处理。如果对脏数据的可能性做好处理,就可以向用户保证缓存语境下的线性一致性,也就是数据 set 完成后只有顺利读取和缓存过期两种情况,不会因为节点更替而导致脏数据情况。
一种典型的脏数据情况下的一致性哈希环如图:
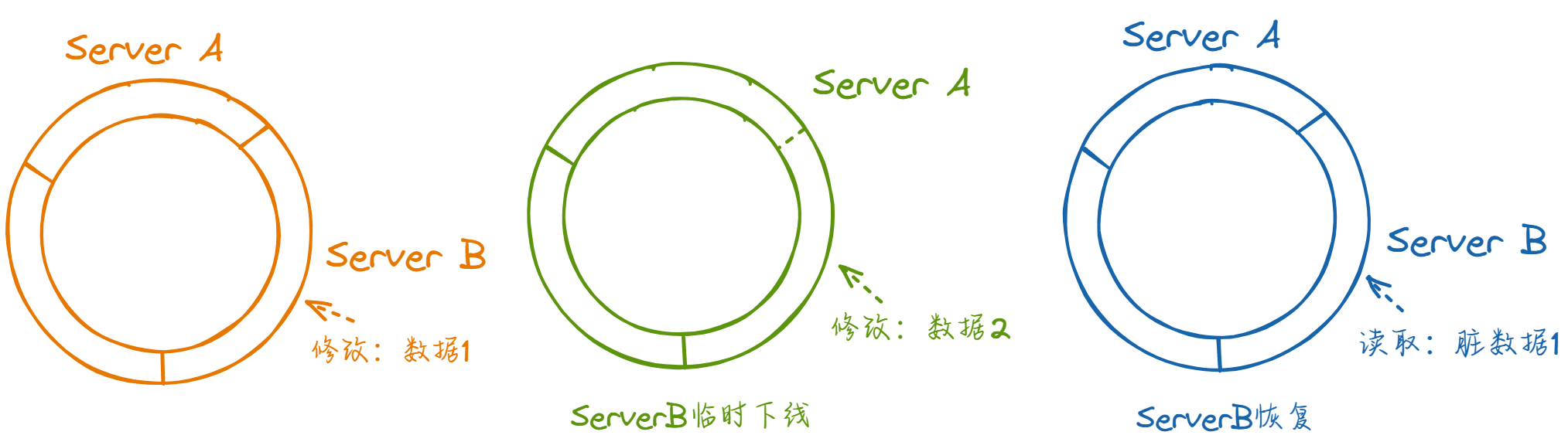
当前哈希环映射到三个节点提供服务,此时向某由server B负责的key1写入数据1。之后 server B因故下线,master 通过心跳判断到此情况,在哈希环上做对应修改。此时 server A在逻辑上就负责了原先由 server B 负责的key1。之后再次向key1执行修改,写入数据2。写入后 server B 恢复,通过 master 注册节点并重新加入服务。假设 server B 只是网络波动,其中数据并未失效,此时客户端若读取key1,就会读取到脏数据1。
研究这个 case,可以总结出:如果一个 key 在上一次被修改到被读到之间产生了影响这个 key 的节点更替,就有可能会产生脏数据。因此我们只需要判断出这种情况,然后进行一些干预即可:
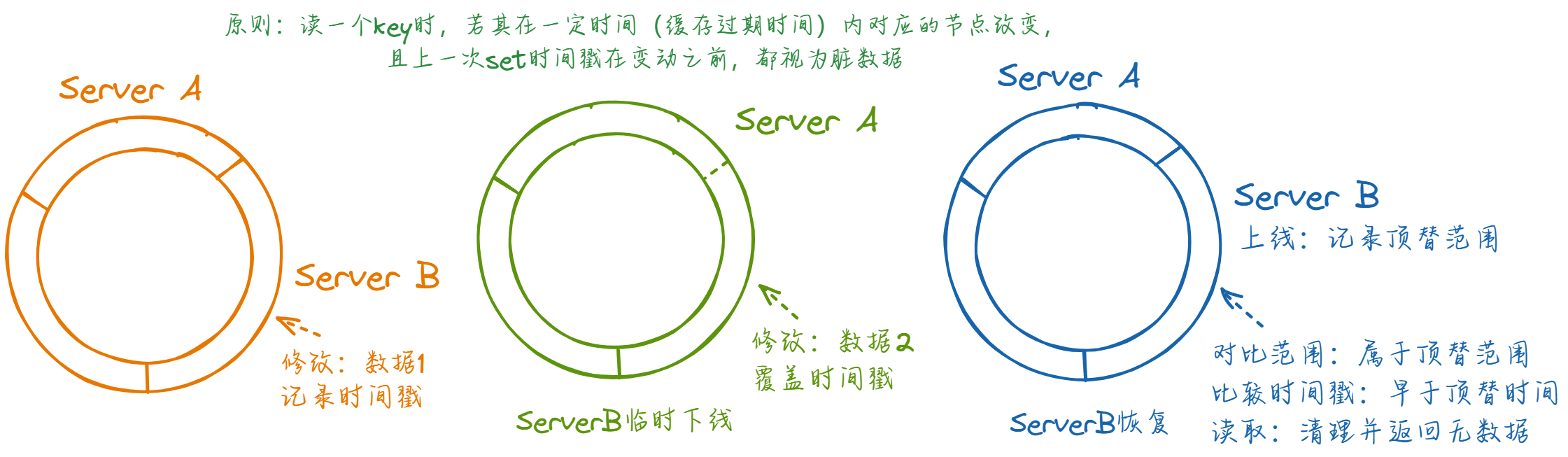
具体来说,我们需要在 get 请求到达时对比上一次影响此key的节点变动(如果有的话)的时间和该 key 在上一次修改时的时间,如果后者早于前者,就需要清理这些数据并返回空。
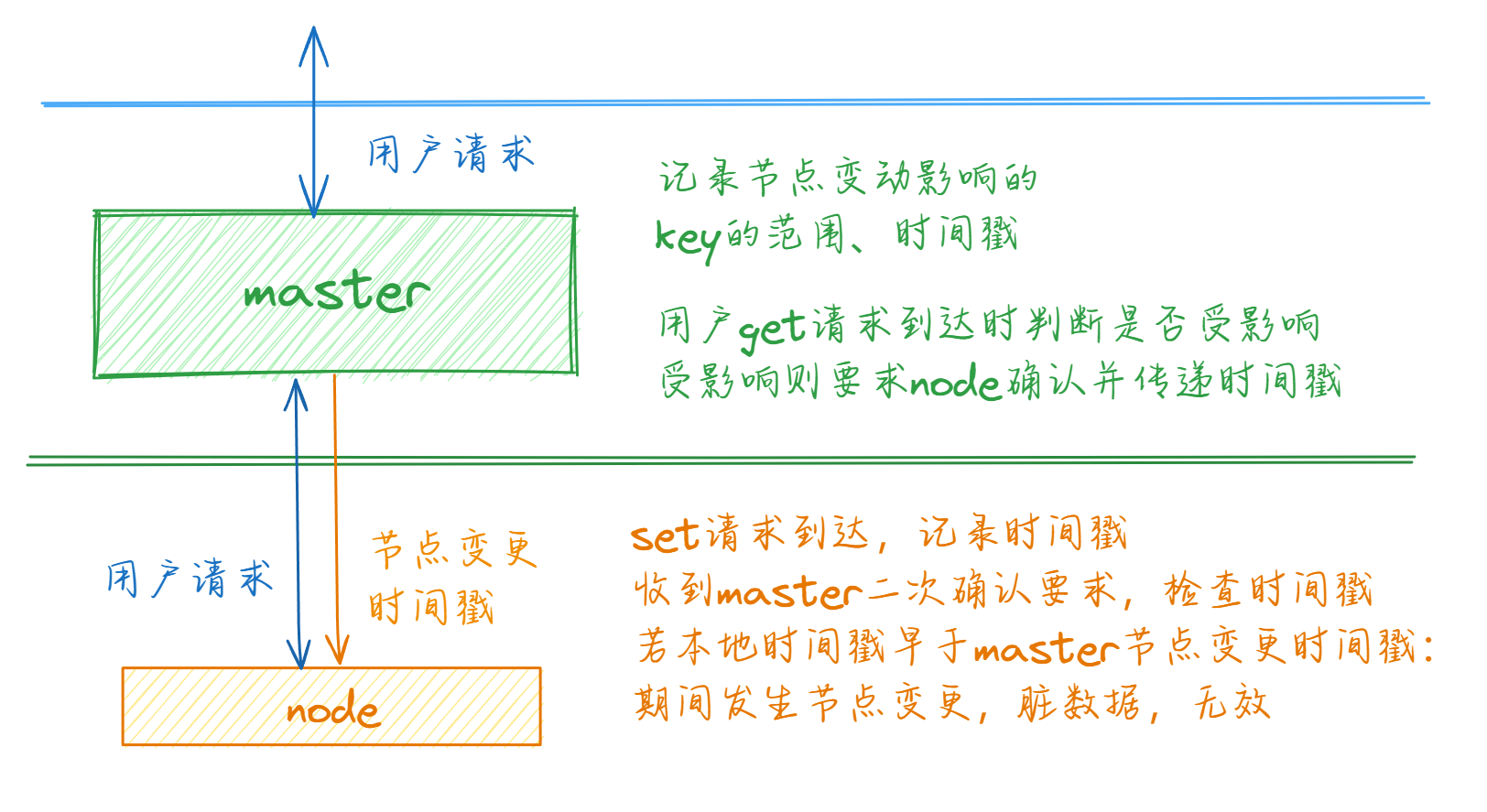
反映到架构的具体实现上,本身 value Entry 就需要记录 set 的时间戳来实现过期失效,因此由 node 本身来完成这个记录; 利用中心化 master 的设计,我们也可以很方便的通过 master 记录节点注册/离线的情况,推断出受影响的 key 的范围,在透传时通过 header 要求 node 进行时间戳二次确认并传递影响的时间戳。
这样,系统就可以在任意的扩缩容、较差的网络环境或更多极端情况下保持可用性和一致性,并且尽可能保证没有脏数据污染影响的数据不受干扰。