
一、概念
这个lab的主要内容是实现一个简单的MapReduce分布式系统。
MapReduce的概念来自google的论文:
论文中有一个非常简明的图片,介绍了MapReduce的基本结构:
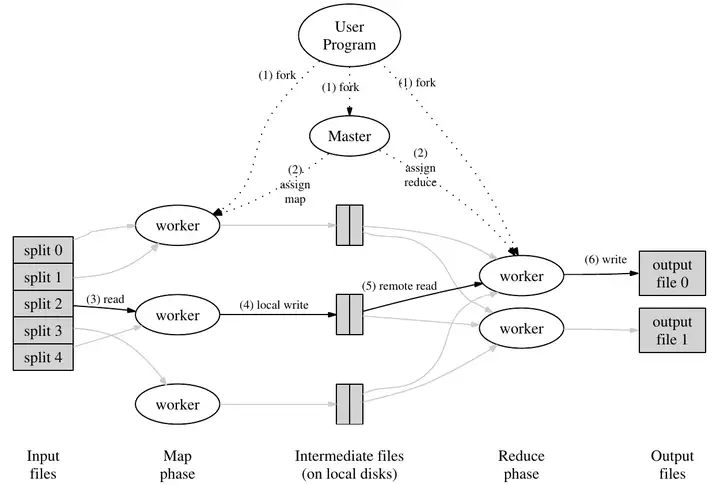
有关信息:
- MapReduce的任务是充分利用分布式的计算机集群,对文件进行任务分割并分配到下游机器分别操作,然后合并结果(本lab不需要使用多台设备,而用多个进程来模拟);
- 为了把任务显式地分配给多台设备处理,要处理的任务必须能够被分解,且合并时正确性不受先后顺序影响;
- MapReduce的下游机群是不能信任的,即需要做容错处理。
具体步骤:
- 为了将任务分发给多台机器完成,需要先将任务拆分,在拆分后针对分片执行用户操作(
Map),生成分布式的中间值intermediate,然后将多台机器的中间值进行合并降维(Reduce),得到结果。因此,用户代码将负责Map和Reduce的操作,而任务的分发调度则由MapReduce框架控制; - 下游机器的程序称为
worker,指向统一的中心节点master(lab中称为coordinator)。worker通过已经实现好的rpc和coordinator交互(本lab中只能worker单向调用coordinator); - 将所需要处理的文件切片(本lab中不用,一个文件作为一个切片即可),然后将一个切片交予一个worker处理。每个worker针对切片调用用户的map函数,生成中间结果;
- 全部Map任务完成后,coordinator开始组织worker进行reduce任务。worker准备好map产生的中间值,调用用户的reduce函数,生成该reduce对应的最后结果输出。
二、项目结构
参考代码
题目提供了一个mrsequential.go供参考,它是mapReduce的非分布式实现,展示了框架具体的功能。在实现worker时可以复制这里的代码。
需要写的代码
需要写的代码在/stc/mr下:
- coordinator.go:不解释,内含一个rpc服务器
- rpc.go:在此定义与rpc有关的请求和返回结构
- worker.go:不解释,内含与coordinator通信的例子
调用结构
- 启动coordinator时会调用外部的mrcoordinator。不需要修改,但要知道它会调用你写的makeCoordinator方法来启动你的coordinator;
- 启动worker时调用外部的mrworker。不需要修改,但需要知道它通过调用你的Worker方法来启动worker,同时将用户函数mapf和reducef传入。
测试与环境
程序只能在linux上测试。
写完代码要运行测试脚本,使用bash /src/main/test-mr.sh
注意事项
- 用户需要的键值对在map阶段以分布式状态存在,而用户要求程序结束后必须按键的hash值储存结果,因此我们必须安排在reduce阶段每个worker处理特定一部分的键值对,不能重复处理。这里采取的解决方案是在map阶段就将中间值结果分成临时文件输出,如mr-X-Y.tmp,其中X表示map任务id,Y表示reduce任务id(也就是键对应的hash%nReduce的结果)。这样在reduce时就可以依据文件名Y的值,选取自己reduce任务需要的文件读取中间值。
- 在coordinator实现过程中一定会用到多线程(goroutine),且worker由rpc调用的coordinator的方法的线程也与coordinator的主线程不同,所以对其共享的数据在访问时一定要加锁。
- lab要求所有任务结束后worker必须关闭,因此任务结束后coordinator不能立即关闭,应等待一段时间,让worker的ping到达后在reply中要求worker自行退出。
- 外部的调用程序会一段时间调用一次你的done方法,判断程序是否运行完成。因此需要在所有任务结束后使得done方法返回true。
三、代码实现
1. Coordinator.go
定义Coordinator类(已经有了),再定义下MapTask和ReduceTask类型,储存map和reduce任务有关的信息:
type MapTask struct {
Id int
FileName string
Stat int // 0: not started 1: working 2: done
StartTime time.Time // for stat 1 only
}
type ReduceTask struct {
Id int
Stat int // 0: not started 1: working 2: done
StartTime time.Time // for stat 1 only
}
type Coordinator struct {
// Your definitions here.
taskNum int //文件数
nReduce int //nReduce
mapTasks []MapTask
reduceTasks []ReduceTask
mappingDone bool
reduceDone bool
reduceInitDone bool
mux sync.Mutex
}
stat码用于coordinator判断任务状态,startTime 记录下任务开始时间便于判断超时。
map任务和reduce任务分别以列表的形式储存。
在coordinator运行时,作为控制核心,应当由其预生成好任务,并且启动循环监测任务状态的go程:
func (c *Coordinator) init(files []string, nReduce int) {
c.taskNum = len(files)
c.nReduce = nReduce
tasks := make([]MapTask, 0)
for i, v := range files {
tasks = append(tasks, MapTask{i, v, 0, time.Now()})
}
c.mapTasks = tasks
go refreshMapping(c)
fmt.Println("初始化完毕,接收到", c.taskNum, "个任务")
}
这个新的go程主要用于检查map任务是否全部完成,然后对正在处理中的任务,判断是否超时。如果超时,则重新设回未分配状态。如果全部任务已完成,则跳转reduce阶段。同时写一个函数用于即时判断任务完成。
// 单独开goRoutine,循环检测任务是否都已经完成,并处理超时任务
func refreshMapping(c *Coordinator) {
for {
done := true
c.mux.Lock()
for i, task := range c.mapTasks {
if task.Stat == 0 {
done = false
}
if task.Stat == 1 {
done = false
if time.Since(task.StartTime)/time.Second > 10 {
c.mapTasks[i].Stat = 0
fmt.Println("Map任务", task.Id, "超时,正在重新配置")
}
}
}
if done {
c.mappingDone = true
fmt.Println("所有mapping任务已完成")
c.setupReducing()
c.mux.Unlock()
break
}
c.mux.Unlock()
time.Sleep(50 * time.Millisecond)
}
}
// 即时检查map是否完成
func (c *Coordinator) checkMappingDone() bool {
for _, task := range c.mapTasks {
if task.Stat != 2 {
return false
}
}
return true
}
接下来就是由worker调用,进行任务分发的部分。由于我们的结构中coordinator是不储存worker状态的,我们只需要实时维护任务的状态,有任意worker调用时分配一个待进行的任务即可。
// Call4Job 处理worker的job请求
func (c *Coordinator) Call4Job(arg *Ask4JobArg, reply *Ask4JobReply) error {
reply.ReplyStat = 3
c.mux.Lock()
if !c.mappingDone {
if !c.checkMappingDone() {
for i, task := range c.mapTasks {
if task.Stat == 0 {
c.mapTasks[i].Stat = 1
c.mapTasks[i].StartTime = time.Now()
reply.ReplyStat = 1
reply.MapperTask = task
reply.ReduceNum = c.nReduce
fmt.Println("分配任务", task.Id, "给worker。")
break
}
}
}
} else {
if c.reduceInitDone && !c.reduceDone && !c.checkReducingDone() {
for i, task := range c.reduceTasks {
if task.Stat == 0 {
c.reduceTasks[i].Stat = 1
c.reduceTasks[i].StartTime = time.Now()
reply.ReplyStat = 2
reply.ReducerTask = task
reply.ReduceNum = c.nReduce
reply.MapNum = c.taskNum
fmt.Println("分配reduce任务", task.Id, "给worker。")
break
}
}
}
}
if c.reduceDone {
reply.ReplyStat = 4
}
c.mux.Unlock()
return nil
}
上述代码同时处理了reduce的情况,之后进行讨论。
由于worker是不受信任的,所以我们只在worker完成分配给它的任务时让它与coordinator联系,并让其储存状态。接收worker通知其已完成map任务的代码:
// Call4FinishMapping worker通知已经完成mapping任务
func (c *Coordinator) Call4FinishMapping(arg *FinishMappingArg, reply *FinishMappingReply) error {
c.mux.Lock()
c.mapTasks[arg.Id].Stat = 2
c.mux.Unlock()
fmt.Println("收到:", arg.Id, "号mapping已完成")
return nil
}
至此处理map的部分就结束了。接下来的部分是针对reduce任务的控制,与map部分基本一致:
// 准备好reduce任务
func (c *Coordinator) setupReducing() {
tasks := make([]ReduceTask, 0)
for i := 0; i < c.nReduce; i++ {
tasks = append(tasks, ReduceTask{i, 0, time.Now()})
}
c.reduceTasks = tasks
go refreshReducing(c)
fmt.Println("reduce初始化完成")
c.reduceInitDone = true
}
// 单独开goRoutine,循环检测任务是否都已经完成,并处理超时任务
func refreshReducing(c *Coordinator) {
for {
done := true
c.mux.Lock()
for i, task := range c.reduceTasks {
if task.Stat == 0 {
done = false
}
if task.Stat == 1 {
done = false
if time.Since(task.StartTime)/time.Second > 10 {
c.reduceTasks[i].Stat = 0
fmt.Println("Reduce任务", task.Id, "超时,正在重新配置")
}
}
}
if done {
c.reduceDone = true
fmt.Println("所有reducing任务已完成,正在发布关闭指令..")
time.Sleep(500)
c.mux.Unlock()
break
}
c.mux.Unlock()
time.Sleep(50 * time.Millisecond)
}
}
// 即时检查reduce是否完成
func (c *Coordinator) checkReducingDone() bool {
for _, task := range c.reduceTasks {
if task.Stat != 2 {
return false
}
}
return true
}
// Call4FinishReducing worker通知已经完成reduce任务
func (c *Coordinator) Call4FinishReducing(arg *FinishReducingArg, reply *FinishReducingReply) error {
c.mux.Lock()
c.reduceTasks[arg.Id].Stat = 2
c.mux.Unlock()
fmt.Println("收到:", arg.Id, "号reduce已完成")
return nil
}
2. woker.go
worker主体放在死循环内,每次循环sleep100毫秒,反复询问coordinator是否有任务或需要退出。从调用的回复中可以得知该任务是map还是reduce任务,执行过程抽取到doMapping和doReducing函数中。
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
for {
reply := Ask4Job()
if reply.ReplyStat == 1 {
task := reply.MapperTask
fmt.Println("worker接受到任务", task.Id)
doMapping(task, mapf, reply.ReduceNum)
}
if reply.ReplyStat == 2 {
task := reply.ReducerTask
fmt.Println("woker接收到reduce任务", task.Id)
doReducing(task, reducef, reply.MapNum)
}
if reply.ReplyStat == 0 {
fmt.Println("coordinator not found")
time.Sleep(500)
}
if reply.ReplyStat == 4 {
fmt.Println("收到退出指令,退出")
break
}
time.Sleep(100 * time.Millisecond)
}
关于Map操作的执行,可以参照lab给出的示例代码。这里主要难点在于对中间变量应该如何处理。
上面提到过,键值对应该通过对键名和nReduce的哈希值求得应该被哪个reduce任务处理。因此在这一阶段就应求出对应的X-Y文件名并储存。储存的方式是用json格式导出到文件。
func doMapping(task MapTask, mapf func(string, string) []KeyValue, nReduce int) {
fmt.Println("开始id为", task.Id, "的map工作。")
filename := task.FileName
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
file.Close()
kva := mapf(filename, string(content))
intermediate := make(map[int][]KeyValue)
for _, keyValue := range kva {
intermediate[ihash(keyValue.Key)%nReduce] = append(intermediate[ihash(keyValue.Key)%nReduce], keyValue)
}
for key, value := range intermediate {
ofile, _ := os.Create("mr-" + strconv.Itoa(task.Id) + "-" + strconv.Itoa(key) + ".tmp")
b, _ := json.Marshal(value)
ofile.Write(b)
ofile.Close()
}
fmt.Println("worker完成map任务", task.Id)
Ask4FinishMapping(task.Id)
}
关于reduce过程,同样可以借鉴给出的示例代码,但也要稍微复杂些。
对以表格一样的形式离散储存的中间量文件,要遍历该reduce任务应处理的文件,转换成键值对数组然后合并。合并完成后也要参照示例代码给出的方法进行一个排序,这样某个键对应的值才能连续排列。将排好的键值对作为参数传给用户的reduce函数,取得输出。
// for sorting by key.
type ByKey []KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
func doReducing(task ReduceTask, reducef func(string, []string) string, nMaps int) {
fmt.Println("开始id为", task.Id, "的reduce工作。")
intermediate := []KeyValue{}
for i := 0; i < nMaps; i++ {
b, err := ioutil.ReadFile("mr-" + strconv.Itoa(i) + "-" + strconv.Itoa(task.Id) + ".tmp")
if err == nil {
var tmp []KeyValue
json.Unmarshal(b, &tmp)
intermediate = append(intermediate, tmp...)
}
}
sort.Sort(ByKey(intermediate))
oname := "mr-out-" + strconv.Itoa(task.Id)
ofile, _ := os.Create(oname)
i := 0
for i < len(intermediate) {
j := i + 1
for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {
j++
}
values := []string{}
for k := i; k < j; k++ {
values = append(values, intermediate[k].Value)
}
output := reducef(intermediate[i].Key, values)
// this is the correct format for each line of Reduce output.
fmt.Fprintf(ofile, "%v %v\n", intermediate[i].Key, output)
i = j
}
ofile.Close()
fmt.Println("worker完成", task.Id, "号reduce任务")
Ask4FinishReducing(task.Id)
}
同样,需要写好和coordinator交互的一些方法:
func Ask4FinishReducing(taskId int) {
reply := FinishReducingReply{}
arg := FinishReducingArg{taskId}
ok := call("Coordinator.Call4FinishReducing", &arg, &reply)
if ok {
} else {
fmt.Printf("call failed!\n")
}
}
func Ask4FinishMapping(taskId int) {
reply := FinishMappingReply{}
arg := FinishMappingArg{taskId}
ok := call("Coordinator.Call4FinishMapping", &arg, &reply)
if ok {
} else {
fmt.Printf("call failed!\n")
}
}
func Ask4Job() Ask4JobReply {
reply := Ask4JobReply{}
arg := Ask4JobArg{}
ok := call("Coordinator.Call4Job", &arg, &reply)
if ok {
return reply
} else {
fmt.Printf("call failed!\n")
return Ask4JobReply{}
}
}
3. rpc.go
这里不需要写实际执行的代码,只需要声明好交互需要用的参数和返回值类型就行。
type FinishReducingArg struct {
Id int
}
type FinishReducingReply struct {
}
type FinishMappingArg struct {
Id int
}
type FinishMappingReply struct {
}
type Ask4JobArg struct {
}
type Ask4JobReply struct {
// 1: mapper 2: reducer 3: no job now 4: quit now 0: coordinator missing
ReplyStat int
MapperTask MapTask
ReducerTask ReduceTask
ReduceNum int
MapNum int
}
在像这样结构比较复杂的机制实现的过程中,从框架总体结构和相关的储存类型开始设计会比较简单。
四、测试和总结
运行测试脚本:

顺利通过测试。
测试中有一个crash test需要注意,它会随机使一个worker不工作,模拟现实的分布式机器情况。所以需要设计好容错机制,本lab主要是超时重新分配机制。
由于本lab的测试环境要求为linux,而开发环境windows下运行goland更优,所以可以采取类似交叉调试的方法,通过IDE的deploy功能同步代码到linux服务器,然后用IDE的终端连接服务器执行编译。
完成这个lab,就实现了一个简单的中心化的执行统一任务的分布式系统。同时对golang的掌握也有一定帮助。