
k8s 动手实现资源预占调度器插件
本文为 unicore 实现的一部分,为 mcyouyou 提供一些高级 k8s 实践功能。
需求背景
k8s 的资源分配和其他 controller 模式的原理相同,是基于声明spec+控制器控制向目标状态转移的形式实现的。换句话说,创建资源时只是声明了它需要的资源预期,控制器(对于 pod 资源来说是调度器)不保证一定能满足对应的资源预期。
然而在常见的多集群资源分配模式下(如unicore),全局资源管理往往需要更精确的控制能力,以提高特定策略下整个集群的装箱率。在高装箱率(90%以上)情况下,如果出现并发下发、资源大范围腾挪等情况,仅依靠原生的单集群声明式+调度器尽可能满足的方法很可能出现超额下发,导致部分 pod 无法满足产生 pending。而很多提高装箱率的策略,会倾向于在短时间将资源下发到同一批集群,大幅提高了并发下发的频次,导致同一时间下发的多批资源满足率极低。
如果能实现一种能提前下发的资源预占机制,就可以在全局资源管理层实现一种下发即刻生效的资源锁,在高装箱率环境下精确控制大规模集群的资源下发,避免超额下发产生的 pending 和后续的跨集群粒度重调度动作。这种预占和指定 IP 调度又有所不同,它保留了集群粒度调度的灵活性,是一种兜底的机制,而非让全局资源管理层完全控制集群粒度的资源调度。
设计
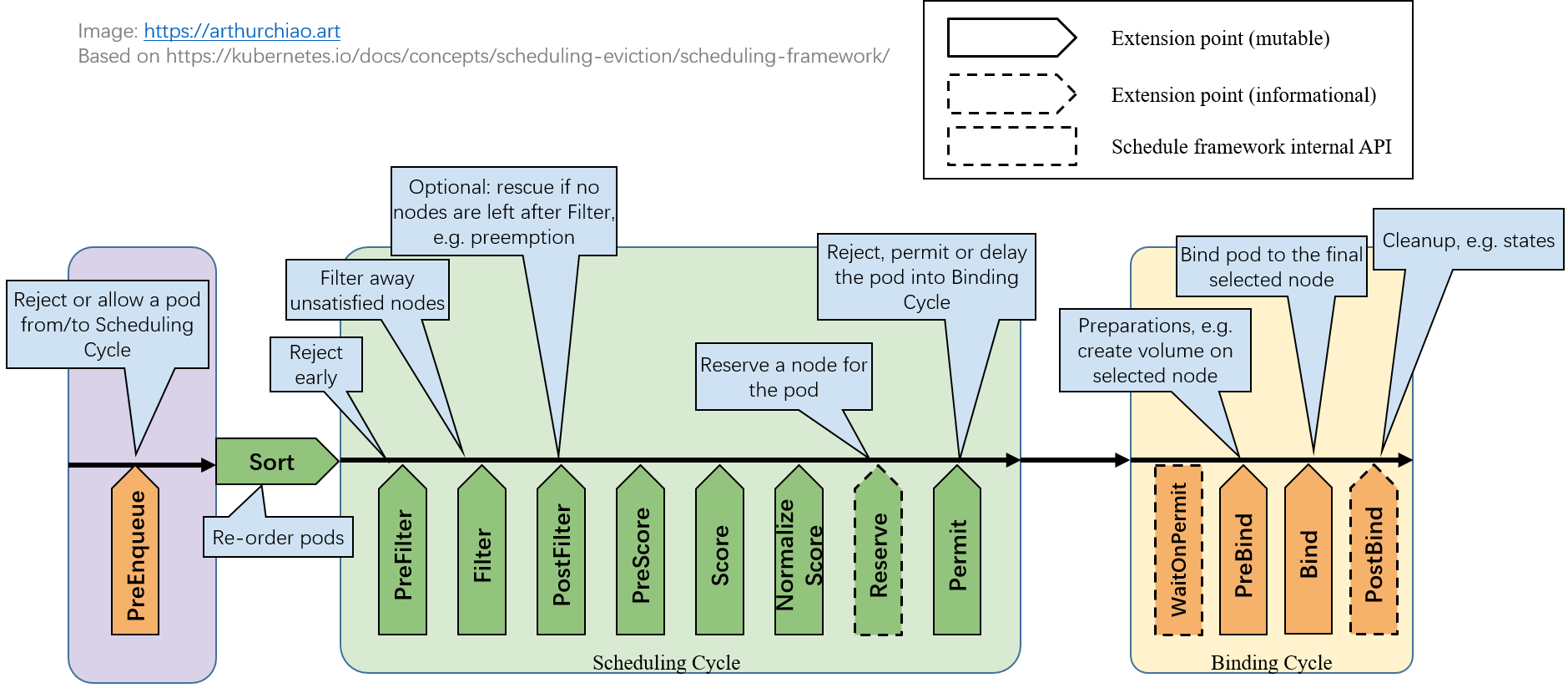
这个插件的设计思路相对简单。需要实现 Filter 和 Reserve 两个插件:
- Filter 扩展点,对于传入的 nodeInfo,除了 pod 全部容器的 cpu、mem 资源需求,还需要加上已注册的资源预占,再和 node 的可用资源比较。在这里过滤掉加上预占资源后不够分配的节点。
- Reserve 扩展点,是在预占的目标 pod 成功获得节点后,标记这个预占已完成(删除预占记录),结束整个预占流程,不管其获得的是否是预期的节点。
然后,我们利用 configMap 来存储已经注册生效的预占。考虑到 CM 的大小限制和特性,其实自定义一个新的 CR 会有更多优势(只需要监听该类型,也可以更好利用上版本机制),但作为一个 PoC 使用 CM 已经足够。这里在调度器插件注册一个 cm informer,监听特定的CM变化。在调度层要尽可能提高性能,因此这里使用 informer 优先走本地缓存。
实现
插件定义、Reservation 结构比较简单,不赘述。这里主要看两个调度器插件:
func (r *ReserveScheduler) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
r.mu.RLock()
defer r.mu.RUnlock()
reservations := r.reservation[nodeInfo.Node().Name]
if len(reservations) > 0 {
klog.Infof("filtering node %s has %d reservations", nodeInfo.Node().Name, len(reservations))
}
freeCPU := nodeInfo.Allocatable.MilliCPU - nodeInfo.Requested.MilliCPU
freeMem := nodeInfo.Allocatable.Memory - nodeInfo.Requested.Memory
reservedCPU, reservedMem := int64(0), int64(0)
needCPU, needMem := int64(0), int64(0)
for _, container := range pod.Spec.Containers {
needCPU += container.Resources.Requests.Cpu().MilliValue()
// mem.Value 返回的为字节,MilliValue 无意义
needMem += container.Resources.Requests.Memory().Value()
}
klog.Infof("handling Filter for pod %s/%s on node %s, needCPU: %v, needMem: %v", pod.Namespace, pod.Name, nodeInfo.Node().Name, needCPU, needMem)
for _, reservation := range reservations {
if time.Now().After(time.Unix(reservation.ExpireAt, 0)) {
klog.Infof("pod %s's reservation expired, skipping", reservation.ReservingPod)
continue
}
reservedCPU += reservation.CPUMilli
reservedMem += reservation.MemMilli
if !(reservation.ReservingPod == pod.Name && reservation.ReservingPodNamespace == pod.Namespace) {
if freeCPU-reservedCPU < needCPU || freeMem-reservedMem < needMem {
klog.Infof("free resource not enough after reservation for pod %s/%s: freeCPU %v - reservedCPU %v < needed %v OR"+
" freeMem %v - reservedMem %v < needed %v, reservations: %+v",
pod.Namespace, pod.Name, freeCPU, reservedCPU, needCPU, freeMem, reservedMem, needMem, reservations)
return framework.NewStatus(framework.Unschedulable, fmt.Sprintf("free resource not enough after reservation:"+
" freeCPU %v - reservedCPU %v < needed %v OR"+
" freeMem %v - reservedMem %v < needed %v", freeCPU, reservedCPU, needCPU, freeMem, reservedMem, needMem))
}
}
}
return framework.NewStatus(framework.Success)
}
Filter 插件要遍历所有的容器,累加关注的资源需求(这里是mem和cpu),然后根据本地通过 informer 事件计算得到的 reservation 缓存,找到非过期且不是本 pod 的预占,从节点的可用资源里扣掉。这里插件的返回要详细附上拒绝的原因,方便后期排查。
func (r *ReserveScheduler) Reserve(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) *framework.Status {
newReservation := make(map[string][]Reservation)
updated := false
r.mu.RLock()
for nodeName, reservations := range r.reservation {
newReservation[nodeName] = make([]Reservation, 0)
for _, reservation := range reservations {
if !(reservation.ReservingPod == p.Name && reservation.ReservingPodNamespace == p.Namespace) {
newReservation[nodeName] = append(newReservation[nodeName], reservation)
} else {
klog.Infof("reserving pod %s was scheduleed to node %s, removing from cm..", p.Name, nodeName)
updated = true
}
}
}
r.mu.RUnlock()
if updated {
err := r.updateCM(newReservation)
if err != nil {
klog.Errorf("update reservation for pod %s/%s err: %v", p.Namespace, p.Name, err)
return framework.NewStatus(framework.Success)
}
}
return framework.NewStatus(framework.Success)
}
Reserve 插件仅做通知作用,这里用来在预占的目标 pod 成功调度到节点后将对应预占记录删掉。
最后需要实现一个清理逻辑,清理掉因为各种原因没有成功最终下发的预占,避免长期占用这个资源:
func (r *ReserveScheduler) cleanExpired() {
for {
time.Sleep(ExpireCheckLoopTime)
r.mu.RLock()
newReservation := make(map[string][]Reservation)
updated := false
for nodeName, reservations := range r.reservation {
newReservation[nodeName] = make([]Reservation, 0)
for _, reservation := range reservations {
if reservation.ExpireAt > time.Now().Unix() {
newReservation[nodeName] = append(newReservation[nodeName], reservation)
} else {
updated = true
}
}
}
r.mu.RUnlock()
if !updated {
continue
}
err := r.updateCM(newReservation)
if err != nil {
klog.Errorf("update cm err, skip cleaning expired: %v", err)
}
}
}
测试
让 ai 写一个测试脚本,成功实现了针对指定节点的资源预占:
[root@dev test]# bash test_reserve_scheduler.sh
==> 准备 namespace
namespace/unicore created
==> 创建 reservation ConfigMap(kind-worker 预留 2c)
configmap/reservation created
==> Step 1: 打满 kind-worker2 (3c)
pod/fill-worker1 created
==> Step 2: 打满 kind-worker3 (3c)
pod/fill-worker2 created
pod/fill-worker1 condition met
pod/fill-worker2 condition met
==> Step 3: 下发普通 pod(3c),理论上不应当有空闲
pod/normal-pod created
normal-pod phase=Pending, node=<none>
✅ 正确:预留资源阻止普通 pod 调度
==> Step 4: 下发被预留 pod(2c)
pod/reserved-pod created
pod/reserved-pod condition met
reserved-pod node=kind-worker
✅ 正确:reserved-pod 使用了被预留节点
==> Step 5: 再下发普通 pod(1.5c)
pod/after-reserve-pod created
pod/after-reserve-pod condition met
after-reserve-pod node=kind-worker
🎉 强化预占测试完成
[root@dev test]# kubectl get po -n unicore
NAME READY STATUS RESTARTS AGE
after-reserve-pod 1/1 Running 0 13s
fill-worker1 1/1 Running 0 21s
fill-worker2 1/1 Running 0 21s
normal-pod 0/1 Pending 0 19s
reserved-pod 1/1 Running 0 14s
I1221 14:09:11.245333 1 reserve.go:171] free resource not enough after reservation for pod unicore/fill-worker1: freeCPU 3900 - reservedCPU 2000 < needed 3000 OR freeMem 16181178368 - reservedMem 0 < needed 0, reservations: [{ReservingPod:reserved-pod ReservingPodNamespace:unicore CPUMilli:2000 MemMilli:0 ExpireAt:1766326747}]