
Golang GMP 并发模型笔记
以前看过,但是居然没有记笔记,遂补
背景
线程与协程首先有所区别。一般语义中,线程是:
- 操作系统的最小调度单元
- 创建销毁和调度由内核完成,在此期间需要切换内核态
而一般语义中的协程是:
- 又称为用户级线程
- 与线程的映射关系是 M : 1
- 创建销毁和调度在用户态完成
- 从属于一个线程,无法并行,一个协程阻塞会导致同一进程的协程无法执行
于是,golang 经过优化,实现了 goroutine 这种特殊的协程:
- 与线程的映射关系是 M : N
- 创建销毁和调度在用户态完成
- 可利用多个线程,实现并行
- 通过调度器,可以实现线程和 goroutine 的动态绑定和调度
- 栈空间大小可以动态扩展
GMP 模型
GMP = Goroutine + Machine + Processor,通过定义这三种概念然后把他们组合起来,针对减少加锁、避免资源分配不均等问题给出了解决方案。
G
- g 就是 goroutine,是对协程的抽象
- g 有自己的运行栈和状态,以及执行的任务函数
- g 需要绑定到 p 才能运行,在 g 的视角中 p 是其 cpu
P
- P 是 processor,是 golang 中的调度器
- p 是 gmp 的中枢,承上启下,实现 g 和 m 的有机结合
- g 只有被 p 调度才能执行
- 对 m 而言,p 是 m 的执行代理,为其提供必要信息(如可执行的g等),隐藏调度细节
- p 的数量决定了 g 最大并行数量,可以用 GOMAXPROCS 设定
M
- m 是 machine,是对协程的抽象
- m 不直接执行 g,而是先和 p 绑定,由其实现代理
- 因为有 g,所以 m 不用和 g 绑死,g 在生命周期中可以跨 m 执行
GMP
一张经典的图:
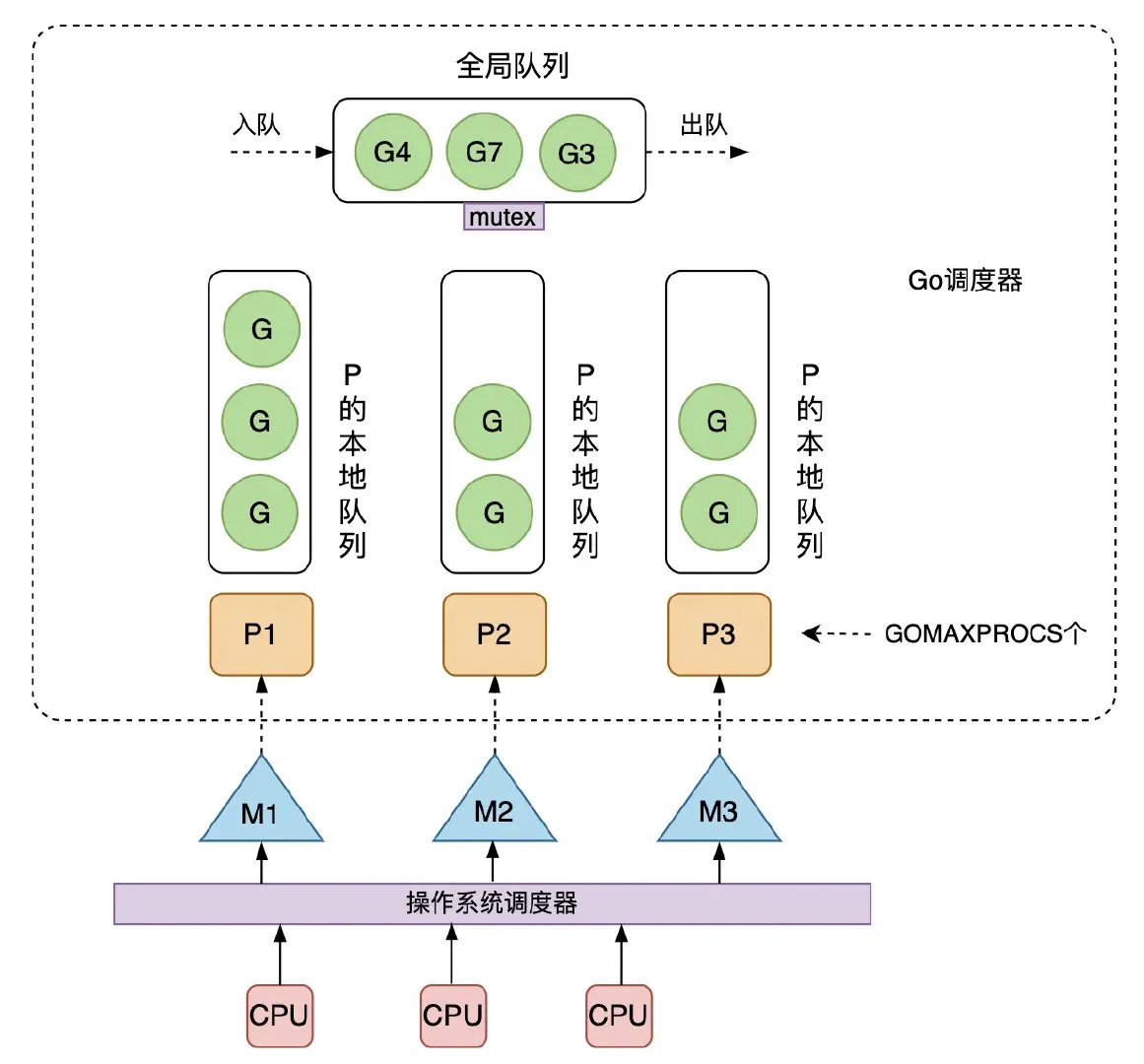
- 全局有多个 M 和 P,但同时并行的 G 的最大数量等于 P 的数量
- G 的存放队列包括本地队列、全局队列和 wait 队列(阻塞后又处于就绪态的队列)
- M 调度 G 时,先取 P 的本地队列,然后再取全局队列,最后取 wait 队列。这样的好处是取本地队列时基本上无锁,减少全局锁竞争
- 为防止 P 的闲忙差异太大,有一个 stealing 机制,本地队列为空的 P 可以从其他 P 的本地队列偷一半 G 到自己的队列
核心数据结构
g
定义如下:
type g struct {
// ...
m *m
// ...
sched gobuf
// ...
}
type gobuf struct {
sp uintptr
pc uintptr
ret uintptr
bp uintptr // for framepointer-enabled architectures
}
- m:执行当前 g 的 m
- sched.sp:指向函数调用栈栈顶( rsp 寄存器的值)
- sched.pc:执行下一条指令地址(PC,RIP)
- sched.ret:保存系统调用的返回值
- sched.bp:指向函数栈帧的起始位置(RBP)
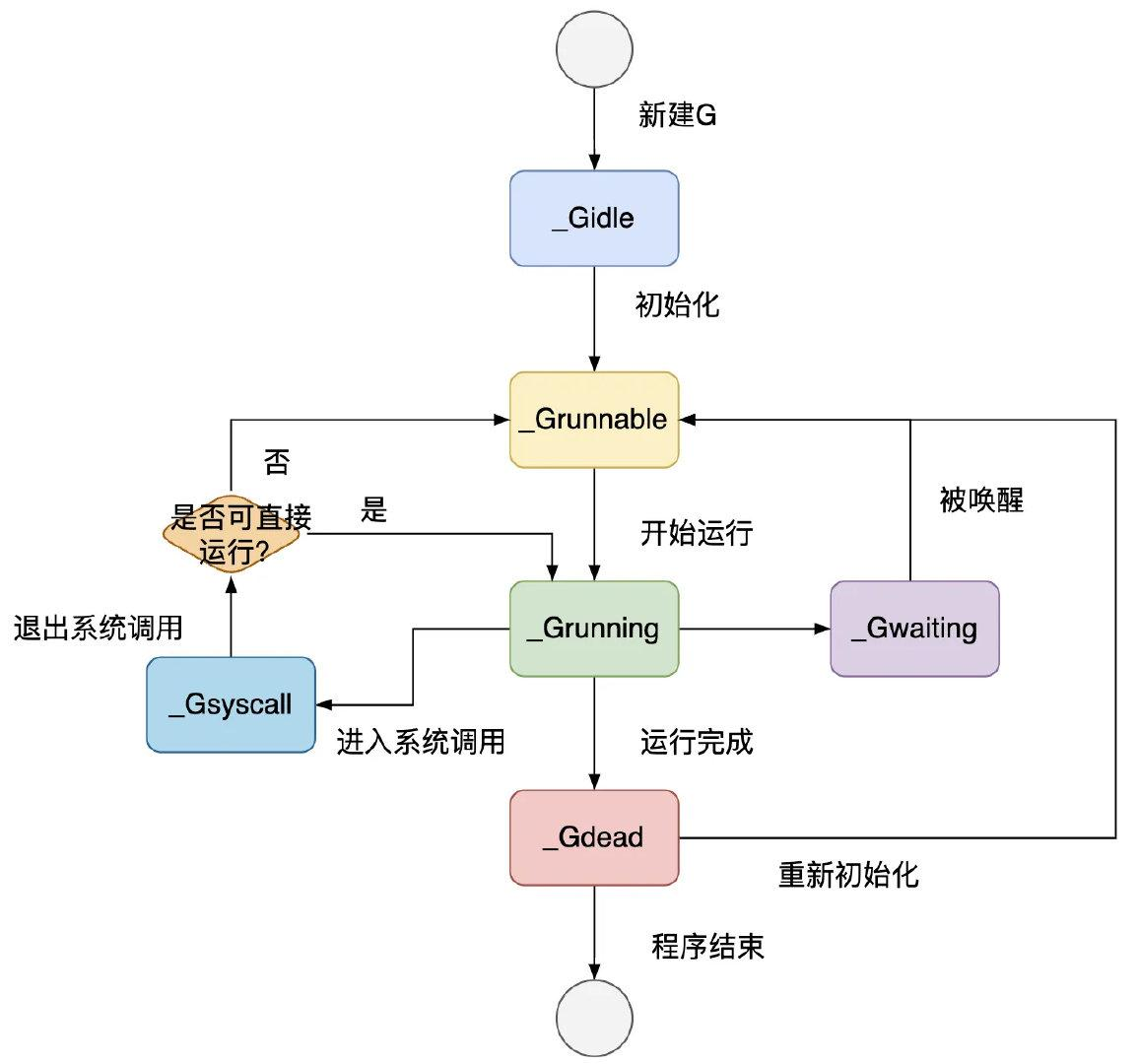
g 的生命周期有下面几种状态:
m
type m struct {
g0 *g // goroutine with scheduling stack
// ...
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
// ...
}
- g0 是一种特殊的调度协程,执行 g 之间的切换调度
- tls:线程本地存储
p
type p struct {
// ...
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
// ...
}
- runq:本地 goroutine 队列
- runnext:下一个可执行的 goroutine
schedt
type schedt struct {
// ...
lock mutex
// ...
runq gQueue
runqsize int32
// ...
}
是全局 goroutine 的封装:
- lock:全局队列的锁
- runq:全局 goroutine 队列
- runqsize:全局队列容量
调度细节
g 与 g0
上面提到 goroutine 分为两类:
- 负责调度普通 g 的 g0,执行固定的调度流程,与 m 一对一绑定
- 执行用户函数的普通 g
m 通过 p 调度执行的 goroutine 永远在 g 和 g0 之间切换,当 g0 找到可执行的 g 时,会调用 gogo 方法,调度 g 执行用户定义的任务。当 g 需要主动让渡或被动调度时,触发 mcall 方法将执行权还给 g0。
调度类型
对于调度器 p 实现从一个 g 切换到另一个 g 的过程,可以分为几种调度类型:
-
主动调度:用户在执行代码中调研会了 runtime.Gosched 方法,当前 g 会主动让出执行权,主动调用 mcall 加入队列等待下次被执行
-
被动调度:g 可能会因为执行条件不满足而陷入阻塞,直到条件满足后 g 才从阻塞中被唤醒,重新进入可执行队列。这种情况下会调用 gopark 方法进入阻塞、通过 goready 方法从阻塞中恢复。
-
正常调度:g 中任务执行完成,g0 会将当前 g 标记为死亡状态,发起新一轮调度
-
交接调度:又叫对 p 的抢占。如果 g 执行系统调度的时间超过指定的时长,且全局的 p 资源比较紧缺,此时会将 p 和 g 解绑,交接出来用于其他 g 的调度。等 g 完成系统调用后会重新进入可执行队列中等待被调度。交接调度时因为是系统调用进入内核态,所以此时 m 也会阻塞在内核态,不能再运行其他 g 了,于是就需要把 p 和这个 g 及其阻塞的 m 断开。此时会由一个全局的第三方 monitor g 来对 p 进行监控和介入。
调度策略
- 为防止全局队列中的协程等太久,p 每执行 61 次本地队列中的协程调度就会从全局队列中拉一个 G 放到 P 的本地队列中
- 准备就绪的网络协程加入全局队列中
- 如果本地队列空了,尝试去从其他 p 里偷一半的 p 到自己的队列中执行
调度时机
调度的时机包括:
- m 启动
- g 退出
- g 主动让出
- gopark 被动等待
- 退出系统调用
- start the world
基于信号的抢占调度
在 1.14 版本 golang 增加了基于信号的抢占式调度,避免一个 goroutine 在 for 死循环等情况下一直占用 cpu 而不主动让出。
M 会注册一个 SIGURG 信号的处理函数,上面提到的全局监控函数会间隔性地进行监控 P,如果发现某 g 独占 p 超过 10ms,就会给M发送抢占信号。M 收到信号以后,会通过先前注册的信号处理函数保存上下文,然后让出线程,最后调用 schedule 函数继续继续执行调度循环。
一些问题
如何理解 P?
P 可以理解为调度器,也可以理解为 M 的上下文,主要负责维护可运行的 goroutine 队列。它把本应分给一个线程的任务和 M 分离开来,这样可以实现一种动态的负载均衡,可以将一个 p 转移给另一个 m 来执行。
P 和 M 何时被创建?
在确定了 P 的最大数量后,runtime 会创建相同数量的 P。对于M,如果没有足够的 M 来关联 P,就会创建一个新的 M。这这情况一般发生在所有的 M 都阻塞时。
启动了大量 goroutine,如何分配?
这些 G 会根据 P 的设定个数,尽量平均地分配到每个 P 的本地队列。如果本地队列都满了,就会把剩下的 G 分配到全局队列。接下来执行 GMP 模型的调度策略:
- 本地队列轮转:每个P维护一个G的队列,P周期性的将G调度到M中执行,执行一小段时间将上下文保存,然后将其放到队尾,再从队首重新取一个出来调度
- 系统调用:一般情况下M个数会略大于P的个数。在G带着M进入系统调用阻塞后,将释放P,让空闲的M获取P,继续执行P中剩下的G。
- 工作量窃取:空闲的P将其他P的G偷一半过来执行,以保持工作量均匀
goroutine 内存泄露的原因和解决方法?
原因:
goroutine 也要维护上下文信息,这些信息会放在 runtime 的堆上,且在 goroutine 销毁前不会释放。如果一个 goroutine 无法结束,同时又在创建新的 goroutine 复用这部分内存,就会造成内存泄露。主要情况有:
- goroutine 正在进行 channel、mutex 等阻塞操作,但是由于逻辑问题一直阻塞
- goroutine 里的业务逻辑进入死循环,资源无法释放
- goroutine 里的业务逻辑进入长时间等待,同时有不断新增的goroutine 进入等待
解决方法:
- 使用 channel ,同时引入超时控制
- 排查:使用 pprof
- 使用 context 做超时控制
总结
GMP 模型是 go 语言的并发模型,通过定义 goroutine G、逻辑处理器 P 和内核线程 M 来实现了高效的并发使用方法。其中 G 是 goroutine,是 go语言中的轻量级并发执行单元,比线程更小更灵活;P 是虚拟的执行单元,负责 goroutine 的调度,维护可运行的 goroutine 队列,并可以在内核线程上转移;M 是内核线程,依赖 P 执行,负责运行其中的 G。在遇到系统调用或网络等阻塞、占用超时等情况下,G 和 P 可以被灵活抢占或重新分配以提高效率。